Seq2Seq 的局限
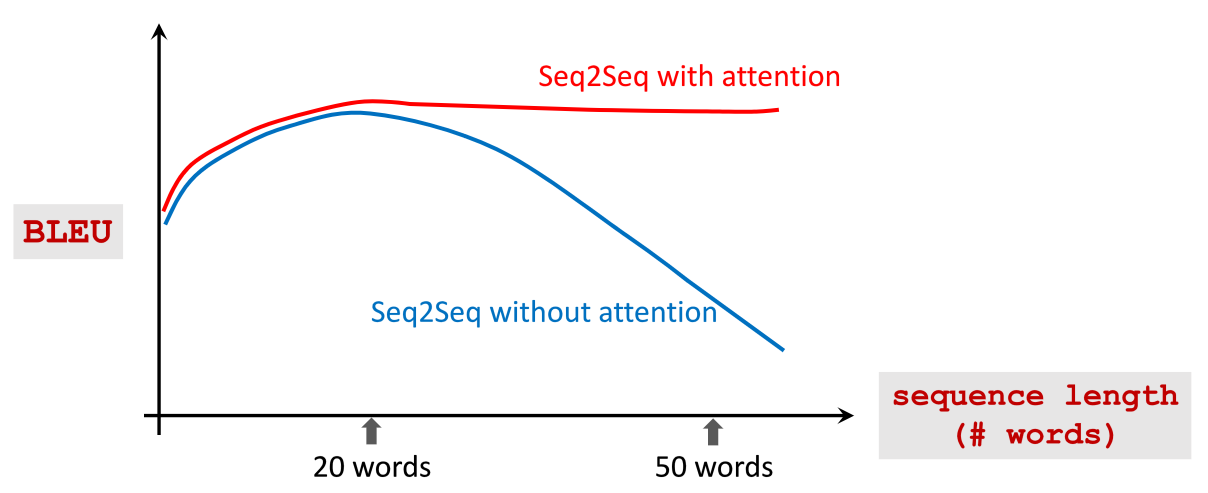
Seq2Seq 仍有记忆问题,当待翻译的句子长度较长时,它会遗忘较早的 。

Attention
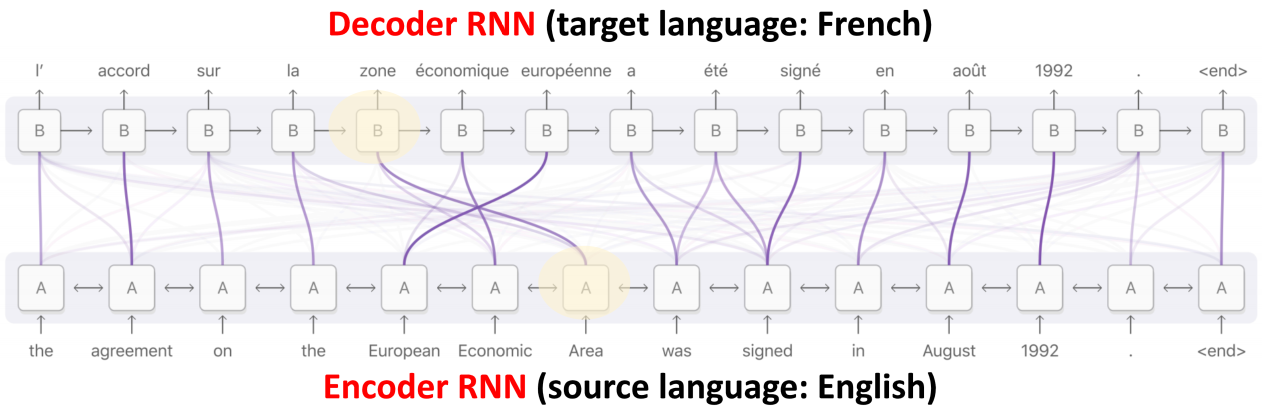
加上 attention,Seq2Seq 不会忘了原始输入,Decoder 每次生成时都回去重新看一遍 Encoder 的所有输入(计算一番),知道要额外关注哪些词,效果很好,但是带来了更多的计算。
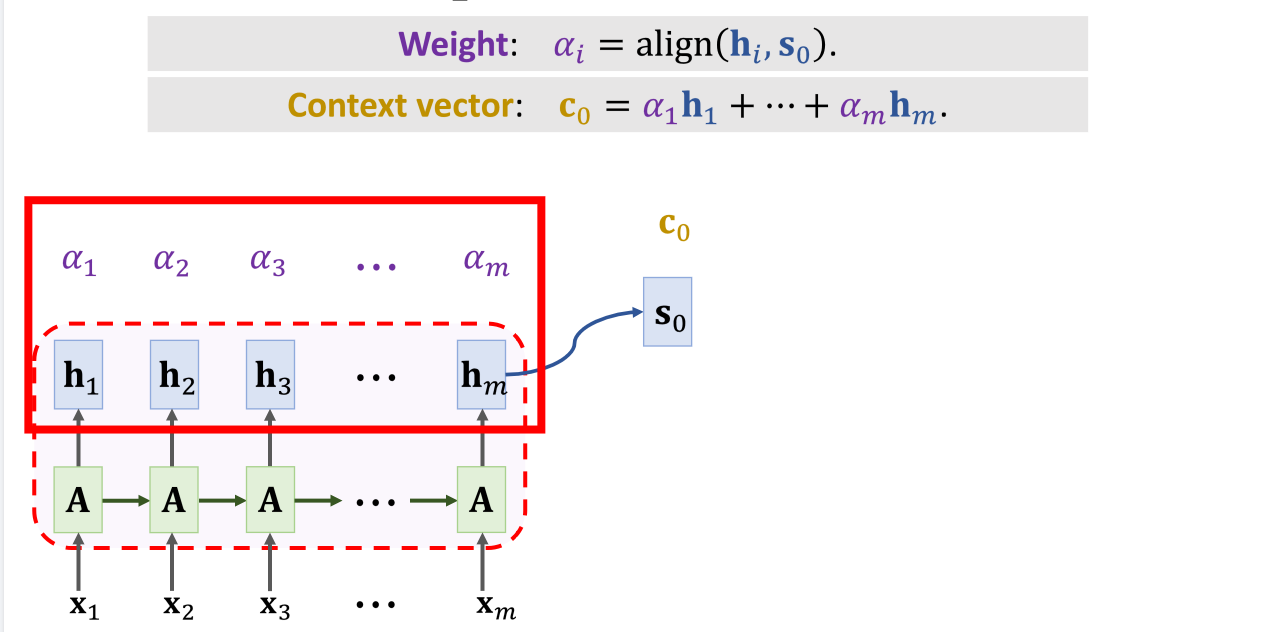
Encoder 的最终输出的 hm 同时也是 Decoder的 s0 ,它和每一个 hi 计算出 m 个 αi ,称为权重向量(weight),α 和 h 点乘(向量相乘相加)得到 c0 称为上下文向量(Context Vector),即 Attention 层的输出(之一)。
权重向量 α 的具体的计算过程是:
-
线性变换:
ki=WK⋅hi, for i=1 to m
qo=WQ⋅s0
-
内积
α~i=kiTq0, for i=1 to m
-
标准化
[α1,α2,…,αm]=Softmax([α~1,α~2,…,α~m])
上下文向量 c0 的计算过程就简单很多,将 m 个 α 和 h 相乘相加。
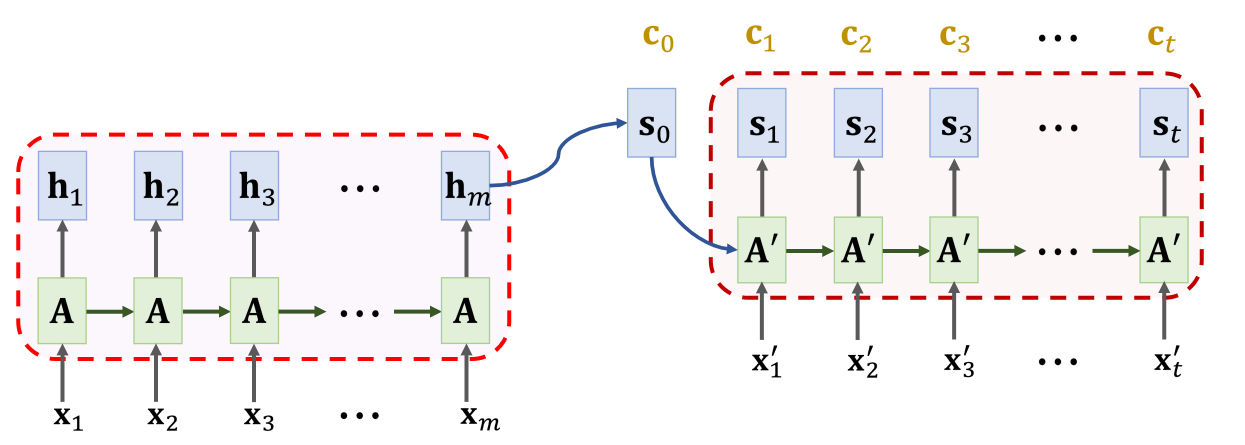
Decoder 端拿到 c0 之后,即可计算 s1 ,具体的方法是:
s1=tanh(A′⋅⎣⎡x1′s0c0⎦⎤+b)
相比 RNN,他多了一个 c0 向量。计算出 s1 之后,拿 s1 和 Encoder 端的 h 向量计算新的 α , α 和 h 点乘得到 c1 ,重复这个过程,直到 Decoder 端输入结束。
复杂度分析
为计算一个 c,我们计算了 m 个权重 α1,…,αm,Decoder 有 t 个 状态,所以总共计算 mt 个权重。
总结
- 标准的 Seq2Seq Decoder 只看当前状态
- 有了 Attention 的 Seq2Seq 会看 Encoder 的所有状态
- 有了 Attention 的 Seq2Seq Decoder 会知道不同程度的关注
- 更高的时间复杂度,标准的 Seq2Seq:O(m+t),有了 Attention 的 Seq2Seq:O(mt)