
不局限于 seq2seq 模型,Self-Attention 思想可在原地计算模型应该关注的地方(Context Vector)。
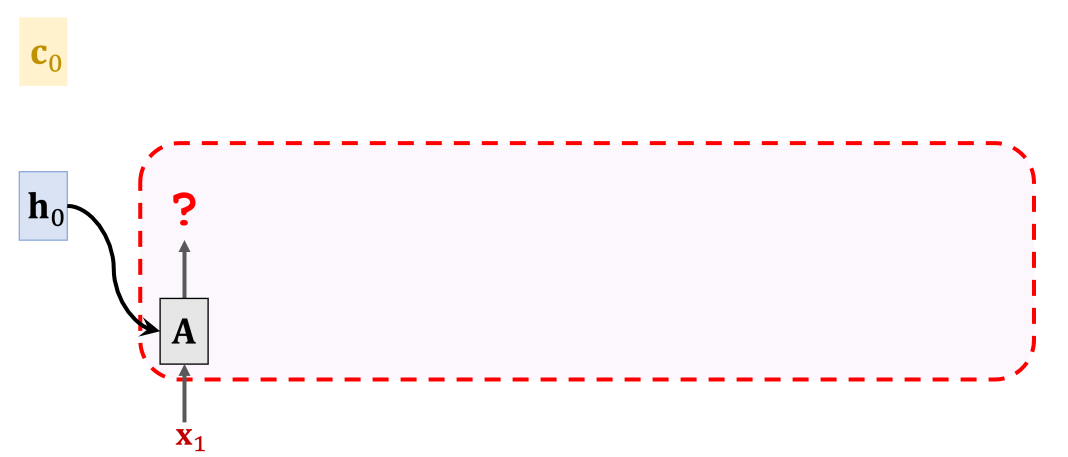
SimpleRNN 是用 和 计算 ,而 Self-Attention 是使用 和 计算 :
当然 此时是零向量,所以
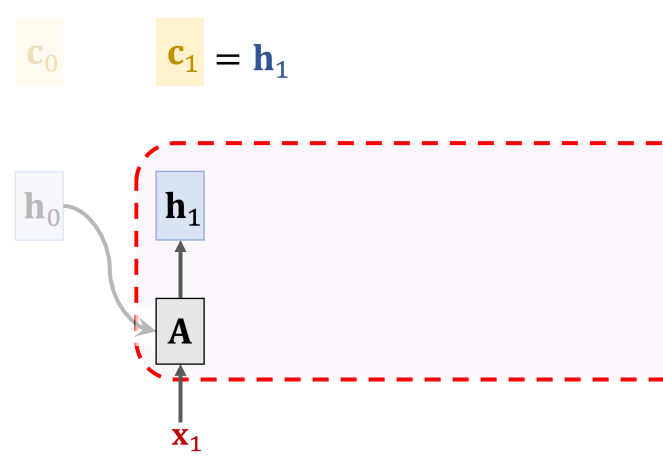
再往下,由 和 计算出

再由 和每一个 计算出 向量

再由 和 向量点乘的到

重复这个过程,直到所有输入都计算一遍。

总结:
- 有了自注意力机制,RNN更不容易遗忘
- 对于新的输入,会去关注相关的上下文
不局限于 seq2seq 模型,Self-Attention 思想可在原地计算模型应该关注的地方(Context Vector)。
SimpleRNN 是用 和 计算 ,而 Self-Attention 是使用 和 计算 :
当然 此时是零向量,所以
再往下,由 和 计算出
再由 和每一个 计算出 向量
再由 和 向量点乘的到
重复这个过程,直到所有输入都计算一遍。
总结:
 (八)LSTM-Attention 实现机器翻译
(八)LSTM-Attention 实现机器翻译
 (六)Attention 是咋回事儿?
(六)Attention 是咋回事儿?


