
Seq2Seq 模型
Seq2Seq 模型,分为两个部分:Encoder 和 Decoder,每个部分都是基于 LSTM。
机器翻译的训练过程
Encoder 的最后一个单元的最终状态参数 和 作为 Decoder LSTM 第一个单元的起始状态参数。 和 里面包含了输入的英语句子 “go away” 的所有特征信息。
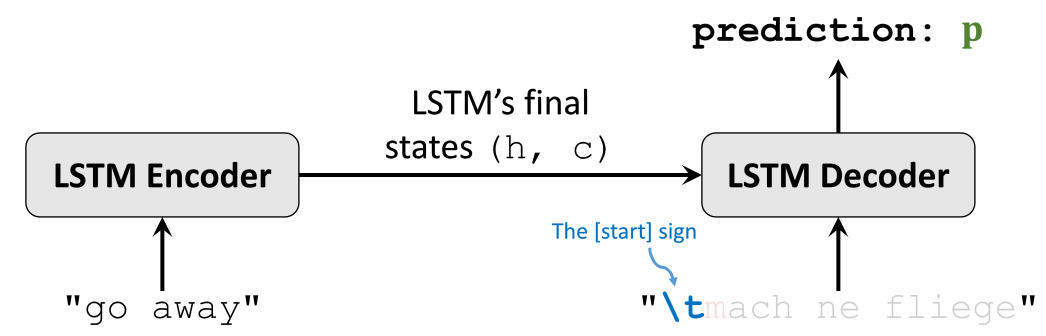
Decoder 第一个输入是一个起始符(如 \t),Decoder 会输出一个概率分布 。

将下一个字母作为标签 y,计算交叉熵作为损失,利用损失计算梯度下降反向传播更新 Encoder Decoder 模型参数。依次循环直到遇到终止字符,结束一个样本的训练。
机器翻译的应用过程
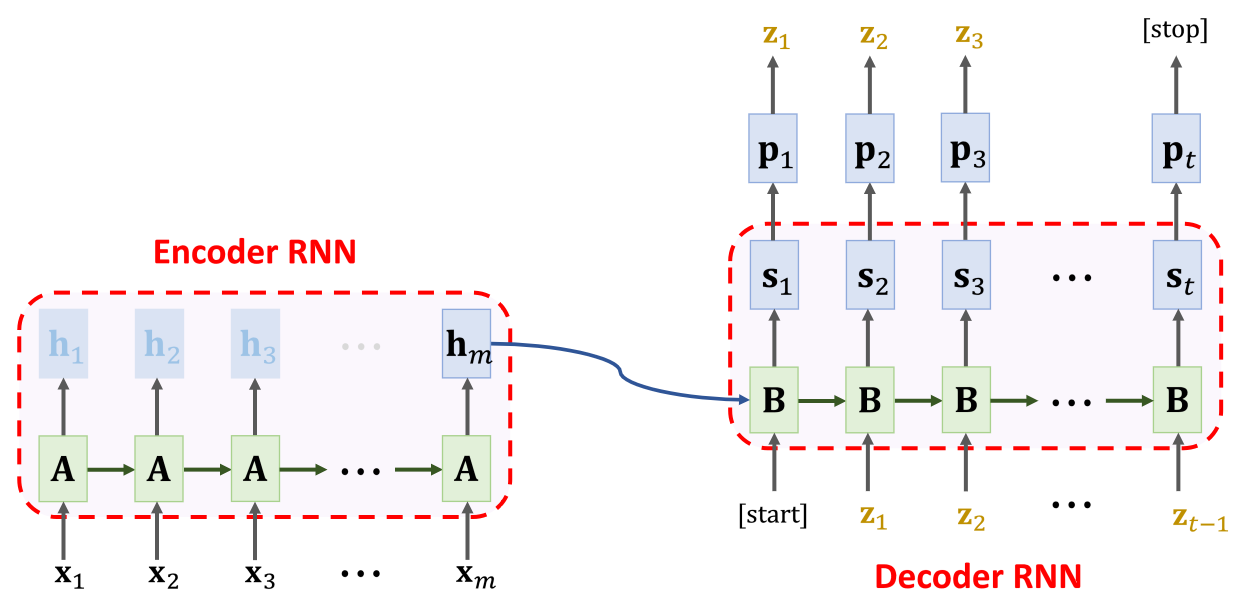
机器翻译的应用过程中,Encoder 端保持不变,Decoder 端逐单元输出的字符可以用来预测下一个字符。
也就是说 [start] 和 更新状态为 ,计算出概率分布 ,得到输出字符 ,再将 和 更新状态为 ,计算出概率分布 ,得到输出字符 ,重复这个 过程,直到最终输出一个 [stop] 为止。
改进 Seq2Seq
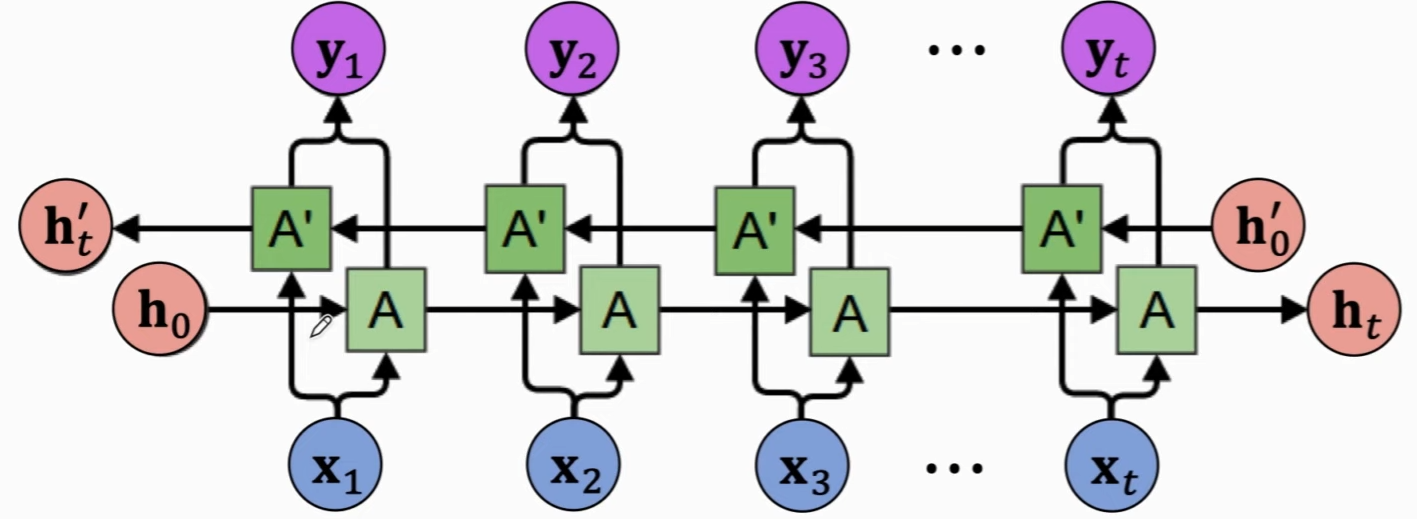
Encoder 端使用 Bi-LSTM
LSTM 仍然具有遗忘特性,如果语句过长,就会有遗忘。
多任务学习
一个 Encoder 对应多个 Decoders,可以更好的训练 Encoder

使用 word level 分词
词的数量很大,所以需要使用 Embedding 层,将 one-hot 向量映射到低维度,不过需要足够大的数据集,才能更好的训练 Embedding 层,不至于 Embedding 层过拟合。
Attention
注意力机制,能极大提高机器翻译的质量。



