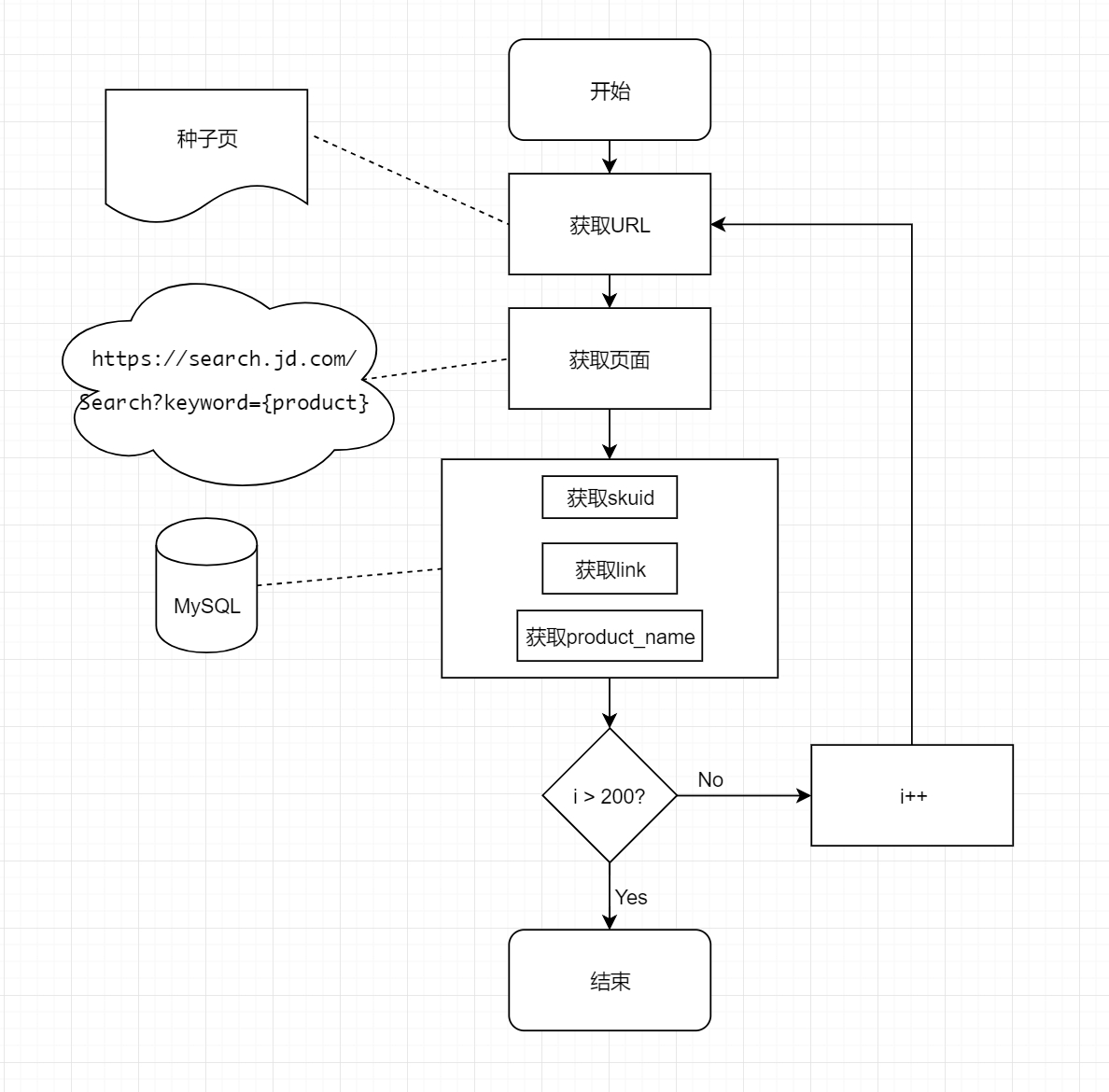
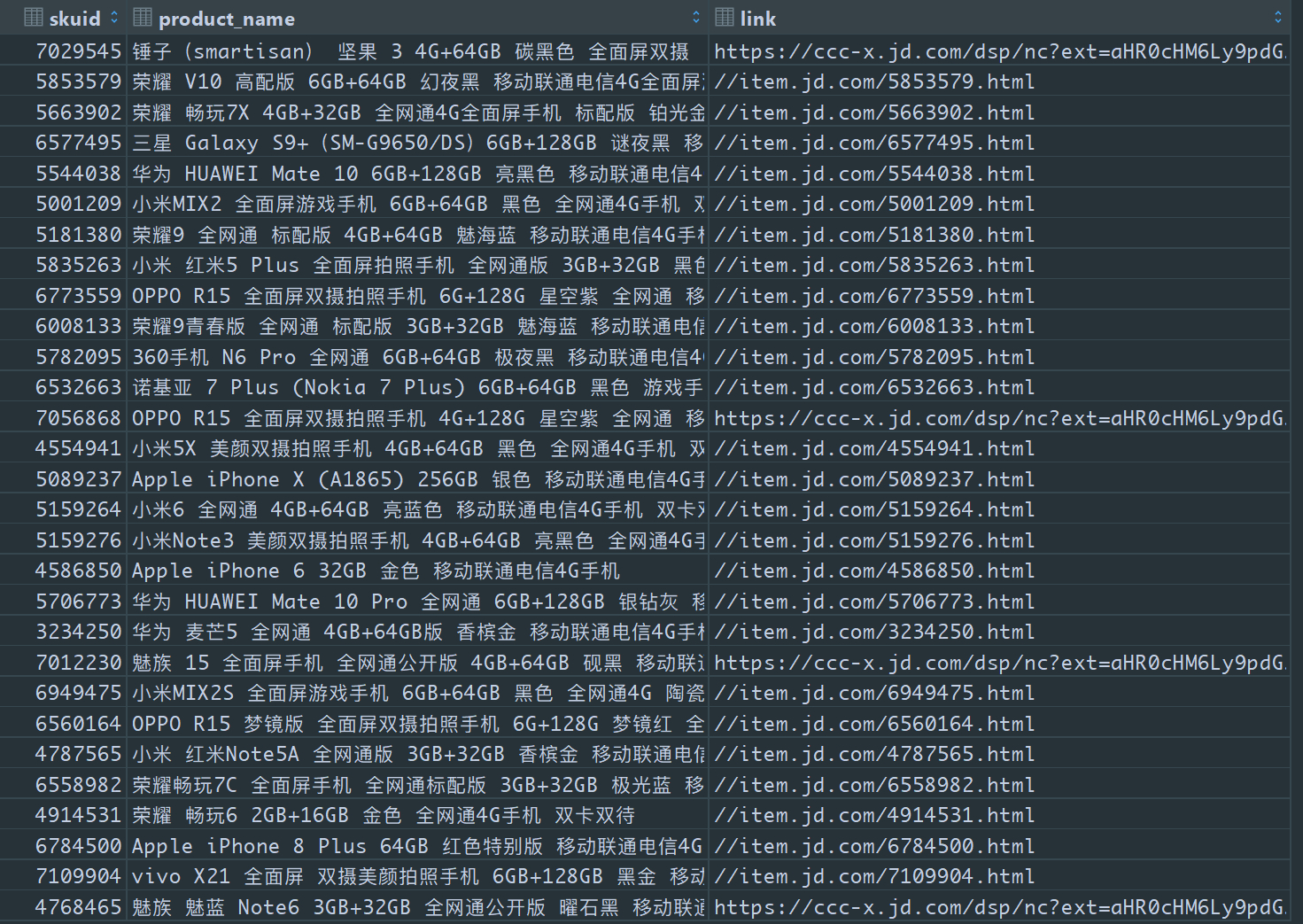
ret_list = [] # 对返回的列表进行遍历 for (a_tags, li_tags) inzip(cellphones, cell_id): # 提取出标题和链接信息 skuid = li_tags.get("data-sku") link = a_tags.get("href") url = "https://item.jd.com/" + str(skuid) + ".html" try: html = requests.get(url, headers=header).text except: print(time.asctime(time.localtime(time.time())) + ": Connection refused by the server..") print("Let me sleep for 5 seconds") print("ZZzzzz...") time.sleep(5) print(time.asctime(time.localtime(time.time())) + ": Was a nice sleep, now let me continue...") continue product_name_whole_html = BeautifulSoup(html, 'lxml') # 从解析文件中通过select选择器定位指定的元素,返回一个列表 product_name_html = product_name_whole_html.select("div.p-name > a") product_name = product_name_html[0].get_text()
data = { 'skuid': skuid, 'product_name': product_name, 'link': link } ret_list.append(data) return ret_list
defget_cellphone_list_whole_jd(): i = 0 while i < 200: list_data = get_cellphones_list(i) for p in list_data: # 获取数据库链接 connection = pymysql.connect(host="localhost", user="root", passwd="123123", db="jd", port=3306, charset="utf8") try: # 获取会话指针 with connection.cursor() as cursor: # 创建sql语句 sql = "insert into jd.jd_product (`skuid`, `product_name`,`link`) values (%s,%s,%s)"