假设机器上有 NVIDIA GPU,且已经安装高版本驱动。
安装过程参考
yum -y install yum-utils && \enable docker
安装过程参考
centos7:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID ) \$distribution /nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo && \
ubuntu:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID ) \$distribution /nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
验证安装:
docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
为避免每次都指定 --gpus ,更改 docker 配置文件 /etc/docker/daemon.json:
{"runtimes" : {"nvidia" : {"path" : "nvidia-container-runtime" ,"runtimeArgs" : []"exec-opts" :["native.cgroupdriver=systemd" ],"default-runtime" : "nvidia"
对于 Kubernetes 的安装,除了使用 kubeadm 之外,还有很多种方案,比如安装 microk8s,kind等,前者的问题是其所有镜像都放在 gcr.io (google container registry)中,没有科学上网是无法拉取镜像的,而且没有提供设置镜像地址的接口,使用起来颇为麻烦;后者是 Kubernets IN Dokcer,是模拟的伪集群,虽然部署简单,但也不在考虑范围之内了。
使用 Rancher,不失为一种更好的方式,它提供易用的 UI,人性化的交互,基于 Docker 容器,即使要删档重来,也不会出现不可预估的意外。
对于 Kubernetes 的版本,Kubeflow 1.3 是在 Kubernetes 1.17 上做的测试,为避免不必要的麻烦,我们也选择 Kubernetes 1.17 版本。
在进一步之前,先配置一下系统设置,比如:
另外,机器上的时间包括时区,要一致。
在这个部分的主要涉及的名词如下:
Rancher Server: 是用于管理和配置 Kubernetes 集群。您可以通过 Rancher Server 的 UI 与下游 Kubernetes 集群进行交互。**RKE(Rancher Kubernetes Engine):**是经过认证的 Kubernetes 发行版,它拥有对应的 CLI 工具可用于创建和管理 Kubernetes 集群。在 Rancher UI 中创建集群时,它将调用 RKE 来配置 Rancher 启动的 Kubernetes 集群。
kubectl: Kubernetes 命令行工具。
Rancher 必须要通过 https 暴露服务,所以最好的解决方案是申请正规(子)域名,来获得权威证书,若是嫌申请流程麻烦,可以生成自签名证书(虽然在后续仍会面临不少麻烦,但是还都是可以克服的)。
这一过程参考
一键生成 ssl 自签名证书脚本:
#!/bin/bash -e help ()echo ' ================================================================ ' echo ' --ssl-domain: 生成ssl证书需要的主域名,如不指定则默认为www.rancher.local,如果是ip访问服务,则可忽略;' echo ' --ssl-trusted-ip: 一般ssl证书只信任域名的访问请求,有时候需要使用ip去访问server,那么需要给ssl证书添加扩展IP,多个IP用逗号隔开;' echo ' --ssl-trusted-domain: 如果想多个域名访问,则添加扩展域名(SSL_TRUSTED_DOMAIN),多个扩展域名用逗号隔开;' echo ' --ssl-size: ssl加密位数,默认2048;' echo ' --ssl-cn: 国家代码(2个字母的代号),默认CN;' echo ' 使用示例:' echo ' ./create_self-signed-cert.sh --ssl-domain=www.test.com --ssl-trusted-domain=www.test2.com \ ' echo ' --ssl-trusted-ip=1.1.1.1,2.2.2.2,3.3.3.3 --ssl-size=2048 --ssl-date=3650' echo ' ================================================================' case "$1 " in help ) help ; exit ;;esac if [[ $1 == '' ]];then help ;exit ;fi "$*" for OPTS in $CMDOPTS ;do echo ${OPTS} | awk -F"=" '{print $1}' )echo ${OPTS} | awk -F"=" '{print $2}' )case "$key " in $value ;;$value ;;$value ;;$value ;;$value ;;$value ;;$value ;;esac done ${CA_DATE:-3650} ${CA_KEY:-cakey.pem} ${CA_CERT:-cacerts.pem} ${SSL_CONFIG:-$PWD /openssl.cnf} ${SSL_DOMAIN:-'www.rancher.local'} ${SSL_DATE:-3650} ${SSL_SIZE:-2048} ${CN:-CN} $SSL_DOMAIN .key$SSL_DOMAIN .csr$SSL_DOMAIN .crtecho -e "\033[32m ---------------------------- \033[0m" echo -e "\033[32m | 生成 SSL Cert | \033[0m" echo -e "\033[32m ---------------------------- \033[0m" if [[ -e ./${CA_KEY} ]]; then echo -e "\033[32m ====> 1. 发现已存在CA私钥,备份" ${CA_KEY} "为" ${CA_KEY} "-bak,然后重新创建 \033[0m" ${CA_KEY} "${CA_KEY} " -bak${CA_KEY} ${SSL_SIZE} else echo -e "\033[32m ====> 1. 生成新的CA私钥 ${CA_KEY} \033[0m" ${CA_KEY} ${SSL_SIZE} fi if [[ -e ./${CA_CERT} ]]; then echo -e "\033[32m ====> 2. 发现已存在CA证书,先备份" ${CA_CERT} "为" ${CA_CERT} "-bak,然后重新创建 \033[0m" ${CA_CERT} "${CA_CERT} " -bak${CA_KEY} -days ${CA_DATE} -out ${CA_CERT} -subj "/C=${CN} /CN=${CA_DOMAIN} " else echo -e "\033[32m ====> 2. 生成新的CA证书 ${CA_CERT} \033[0m" ${CA_KEY} -days ${CA_DATE} -out ${CA_CERT} -subj "/C=${CN} /CN=${CA_DOMAIN} " fi echo -e "\033[32m ====> 3. 生成Openssl配置文件 ${SSL_CONFIG} \033[0m" ${SSL_CONFIG} <<EOM [req] req_extensions = v3_req distinguished_name = req_distinguished_name [req_distinguished_name] [ v3_req ] basicConstraints = CA:FALSE keyUsage = nonRepudiation, digitalSignature, keyEncipherment extendedKeyUsage = clientAuth, serverAuth EOM if [[ -n ${SSL_TRUSTED_IP} || -n ${SSL_TRUSTED_DOMAIN} ]]; then ${SSL_CONFIG} <<EOM subjectAltName = @alt_names [alt_names] EOM "," ${SSL_TRUSTED_DOMAIN} )${SSL_DOMAIN} )for i in "${!dns[@]} " ; do echo DNS.$((i+1 )) = ${dns[$i]} >> ${SSL_CONFIG} done if [[ -n ${SSL_TRUSTED_IP} ]]; then ${SSL_TRUSTED_IP} )for i in "${!ip[@]} " ; do echo IP.$((i+1 )) = ${ip[$i]} >> ${SSL_CONFIG} done fi fi echo -e "\033[32m ====> 4. 生成服务SSL KEY ${SSL_KEY} \033[0m" ${SSL_KEY} ${SSL_SIZE} echo -e "\033[32m ====> 5. 生成服务SSL CSR ${SSL_CSR} \033[0m" ${SSL_KEY} -out ${SSL_CSR} -subj "/C=${CN} /CN=${SSL_DOMAIN} " -config ${SSL_CONFIG} echo -e "\033[32m ====> 6. 生成服务SSL CERT ${SSL_CERT} \033[0m" in ${SSL_CSR} -CA ${CA_CERT} \${CA_KEY} -CAcreateserial -out ${SSL_CERT} \${SSL_DATE} -extensions v3_req \${SSL_CONFIG} echo -e "\033[32m ====> 7. 证书制作完成 \033[0m" echo echo -e "\033[32m ====> 8. 以YAML格式输出结果 \033[0m" echo "----------------------------------------------------------" echo "ca_key: |" $CA_KEY | sed 's/^/ /' echo echo "ca_cert: |" $CA_CERT | sed 's/^/ /' echo echo "ssl_key: |" $SSL_KEY | sed 's/^/ /' echo echo "ssl_csr: |" $SSL_CSR | sed 's/^/ /' echo echo "ssl_cert: |" $SSL_CERT | sed 's/^/ /' echo echo -e "\033[32m ====> 9. 附加CA证书到Cert文件 \033[0m" ${CA_CERT} >> ${SSL_CERT} echo "ssl_cert: |" $SSL_CERT | sed 's/^/ /' echo echo -e "\033[32m ====> 10. 重命名服务证书 \033[0m" echo "cp ${SSL_DOMAIN} .key tls.key" ${SSL_DOMAIN} .key tls.keyecho "cp ${SSL_DOMAIN} .crt tls.crt" ${SSL_DOMAIN} .crt tls.crt
复制以上代码另存为 create_self-signed-cert.sh 或者其他您喜欢的文件名。
脚本参数:
--ssl-domain: 生成ssl证书需要的主域名,如不指定则默认为www.rancher.local,如果是ip访问服务,则可忽略;
比如:
mkdir sslcertcd sslcert
#### 安装 Rancher
这里使用【单节点安装】的方式,基于 docker 镜像,搭建 Rancher,然后使用 Rancher 搭建 Kubernetes
而不采用基于现有的 Kubernetes 搭建 Rancher 的方式,也就是【高可用安装】
以下具体的参数说明请参考6
docker run -d --privileged --restart=unless-stopped \"/container/certs" \log /rancher/auditlog:/var/log /auditlog \
完事儿后,等待一会儿,不出意外的话,即可访问 80 和 443 端口。
通过浏览器进入 Rancher 设定密码界面。
如果密码遗忘,可以通过
$ docker exec <container_id> reset-password
重置密码。
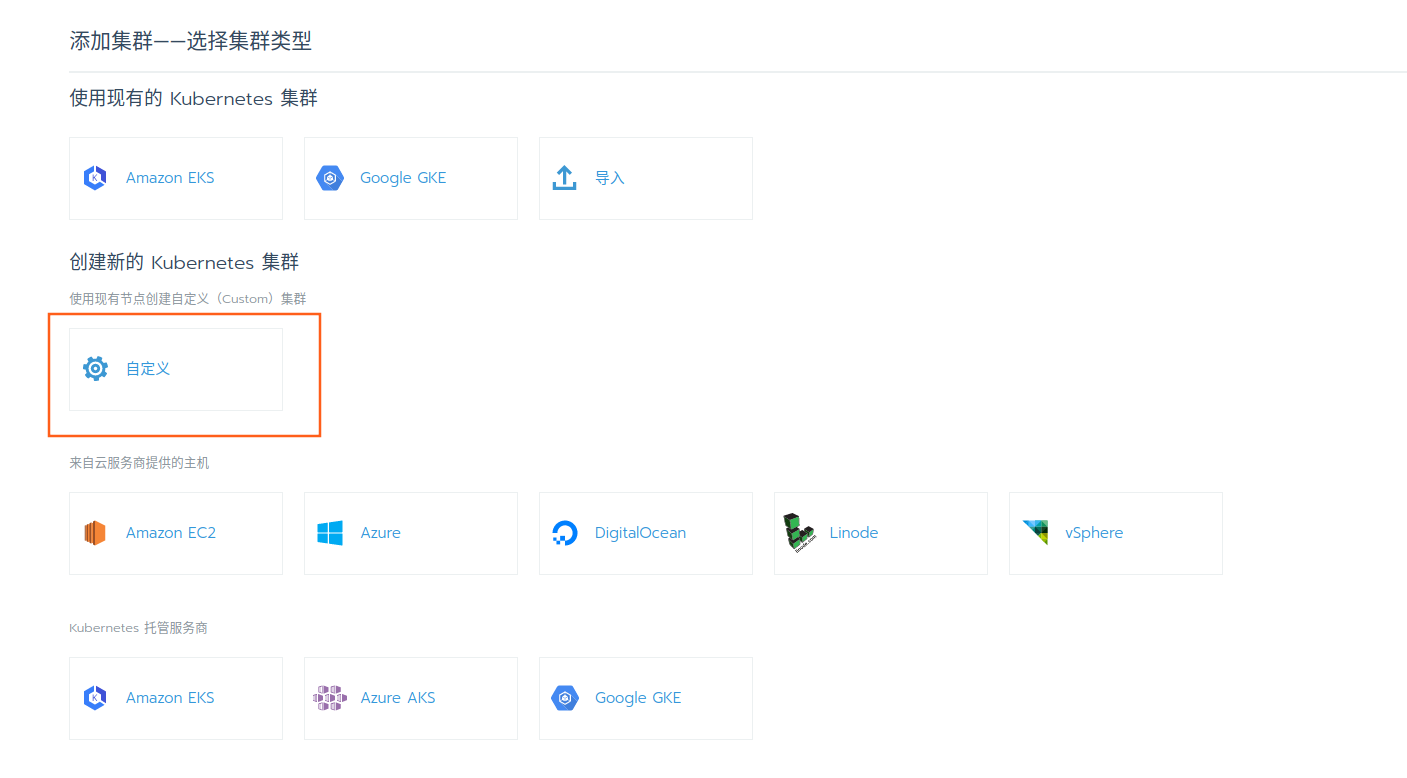
初始密码之后,进入管理界面,添加自定义集群
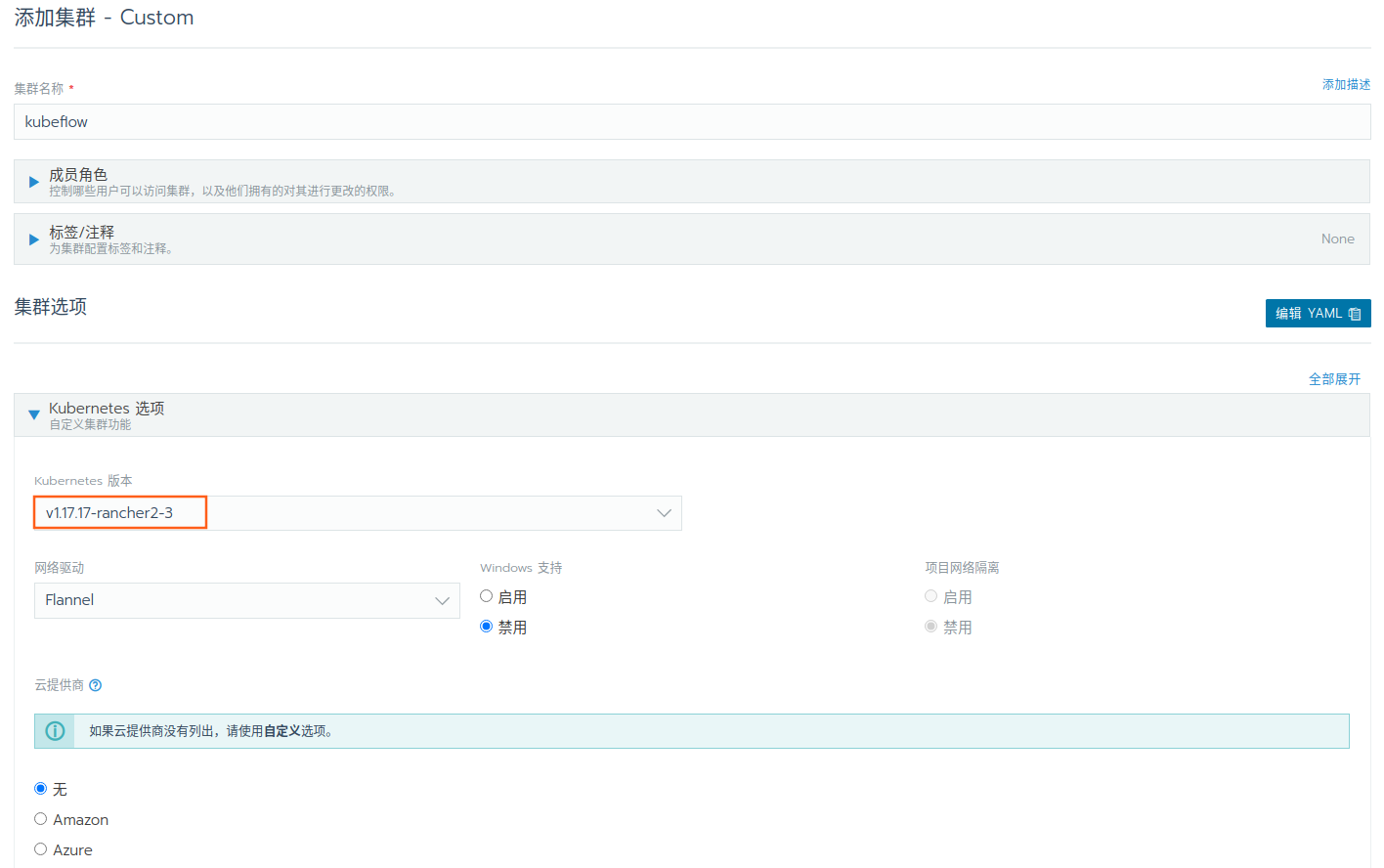
设定集群名称,选定 Kubernetes 版本之后,网络驱动可以选择 Flannel(其他的可能也行但是没有试过),其余均保持默认即可。
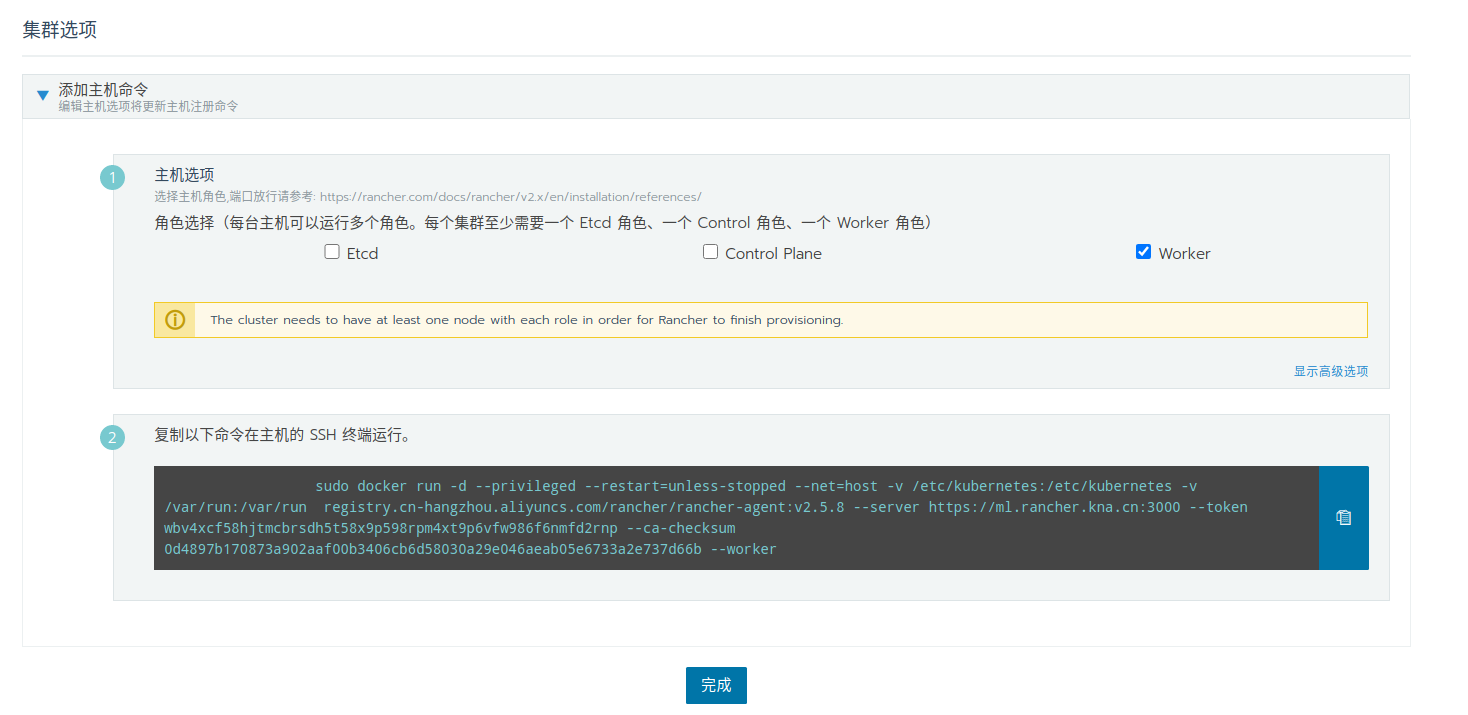
然后就到了集群选项页,按照说明,在其他机器上执行创建 docker 容器的命令,添加子节点。
每台主机可以运行多个角色。每个集群至少需要一个 Etcd 角色、一个 Control 角色、一个 Worker 角色。
最佳实践是将 Etcd 角色 和 Control 角色单独放置于一台空闲机器。
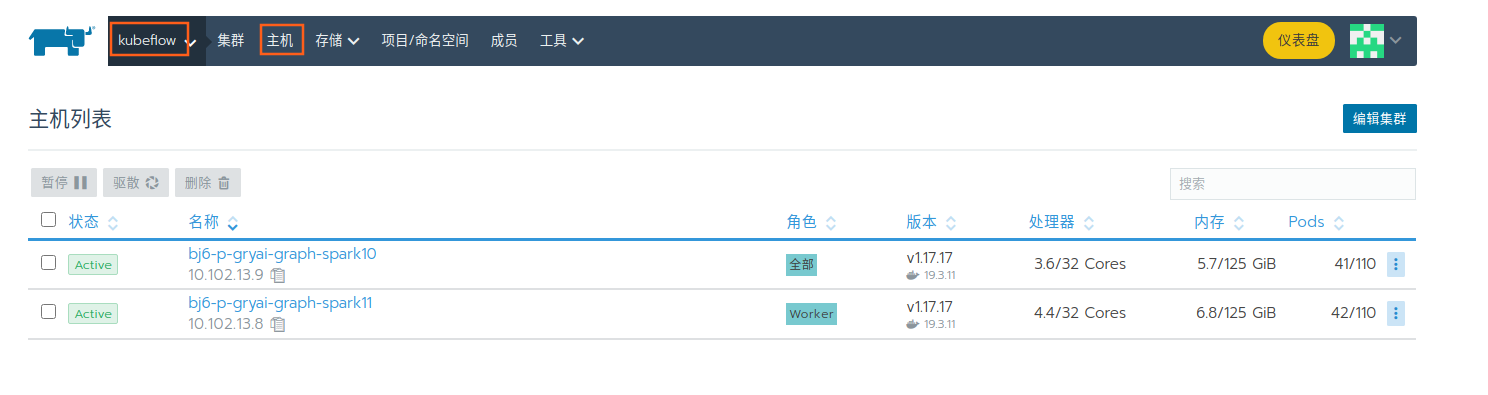
等待一段时间,不出意外的话,点击主机,即可看见添加的节点
为避免使用 kubectl 命令行时提示:
Unable to connect to the server : x509: certificate relies on legacy Common Name field, use SANs or temporarily enable Common Name matching with GODEBUG=x509ignoreCN=0
此错误跟本地的go环境有关。
设置一个环境变量(添加到 ~/.bashrc 或其他地方):
$ export GODEBUG=x509ignoreCN=0
下载 kubectl 二进制文件:
下载地址1: http://mirror.cnrancher.com/
下载地址2:
其中版本号可根据实际情况修改
将至软链到某 $PATH 目录,比如:
sudo ln -s $(pwd )/kubectl /usr/bin/kubectl
在集群页面,点击 Kubeconfig 文件
在主节点上创建
mkdir ~/.kube
文件夹和文件。
编辑内容为浏览器中打开的窗口展示的内容,这样 kubectl 就知道如何找到集群了。
将以下内容保存成 nvidia-device-plugin.yml
PS: 如果你使用 nvidia 官方提供的这个 yml 文件,可能会出现主节点没有此 pod 的情况。
apiVersion: apps/v1 kind: DaemonSet metadata: name: nvidia-device-plugin-daemonset namespace: kube-system spec: selector: matchLabels: name: nvidia-device-plugin-ds updateStrategy: type: RollingUpdate template: metadata: annotations: scheduler.alpha.kubernetes.io/critical-pod: "" labels: name: nvidia-device-plugin-ds spec: tolerations: - key: CriticalAddonsOnly operator: Exists - key: nvidia.com/gpu operator: Exists effect: NoSchedule - key: node-role.kubernetes.io/master effect: NoSchedule priorityClassName: "system-node-critical" containers: - image: nvcr.io/nvidia/k8s-device-plugin:v0.9.0 name: nvidia-device-plugin-ctr args: ["--fail-on-init-error=false" ]securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL" ]volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins volumes: - name: device-plugin hostPath: path: /var/lib/kubelet/device-plugins
然后执行
$ kubectl apply -f nvidia-device-plugin.yml
可以通过以下命令、或 rancher 面板追踪 pods 的创建状态:
$ kubectl get pods -n kube-system | grep nvidia
有几台机器,就会有几个 pods 被创建。
最简单的方式,是设置本地存储:
$ kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml
默认会在 /opt/local-path-provisioner 存储数据,要修改的话,根据 https://github.com/rancher/local-path-provisioner 所述,克隆此项目:
$ git clone https://github.com/rancher/local-path-provisioner.git --depth 1
编辑此文件,然后执行
$ kubectl apply -f deploy/local-path-storage.yaml
你可以通过命令、或 rancher 面板
$ kubectl -n local-path-storage get pod
查看状态。
启动后,需要在 rancher 面板中,将本地存储设为默认PV。
或者使用 kubectl 命令设置为默认PV:改变默认 StorageClass | Kubernetes
使用自签名证书的坏处就是,在容器内部无法通过设置 hosts 解析自定义域名。
可能会出现
ERROR: https://rancher.my.org/ping is not accessible (Could not resolve host: rancher.my.org)
的问题。
要解决这个问题,可以在环境中搭建一个 dns 服务器,配置正确的域名和 IP 的对应关系,然后将每个节点的nameserver指向这个 dns 服务器。
或者使用 HostAliases,给关键的几个容器(如 cattle-cluster-agent、cattle-node-agent)打补丁(patch)
kubectl -n cattle-system patch deployments cattle-cluster-agent --patch '{ "spec": { "template": { "spec": { "hostAliases": [ { "hostnames": [ "rancher.xxx.cn" ], "ip": "10.1***3.17" } ] } } } }' '{ "spec": { "template": { "spec": { "hostAliases": [ { "hostnames": [ "rancher.xxx.cn" ], "ip": "10.1***3.17" } ] } } } }'
完事儿后可以使用如下命令、或 rancher 面板追踪状态和进度
$ kubectl get pods -n cattle-system
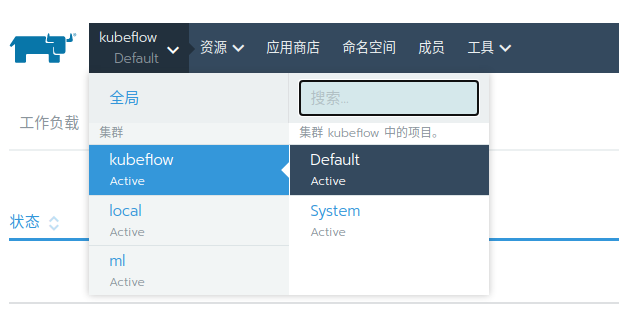
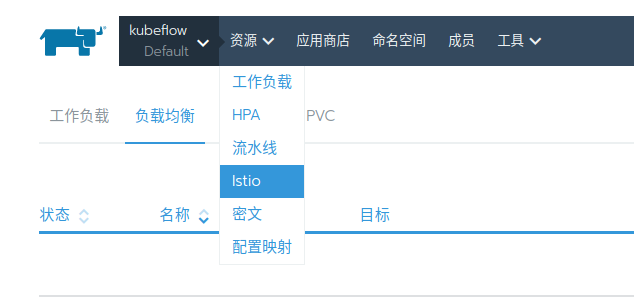
点击 Default 项目
点击 资源 -> istio,保持默认,选择启用
可以使用命令、或 rancher 面板
$ kubectl get pods -n istio-system
来追踪状态和进度。
Rancher 没有默认的证书签名者,在直接安装 Kubeflow 后,pod: cache-server 会面临
Unable to attach or mount volumes: unmounted volumes=[webhook-tls-certs], unattached volumes=[istio-data istio-envoy istio-podinfo kubeflow-pipelines-cache -token-7 pwl7 webhook-tls-certs istiod-ca-cert]: timed out waiting for the condition
的错误,原因是 cert-manager 没有 Issuer 权限,所以有必要在安装之前添加两个参数,方法如下:
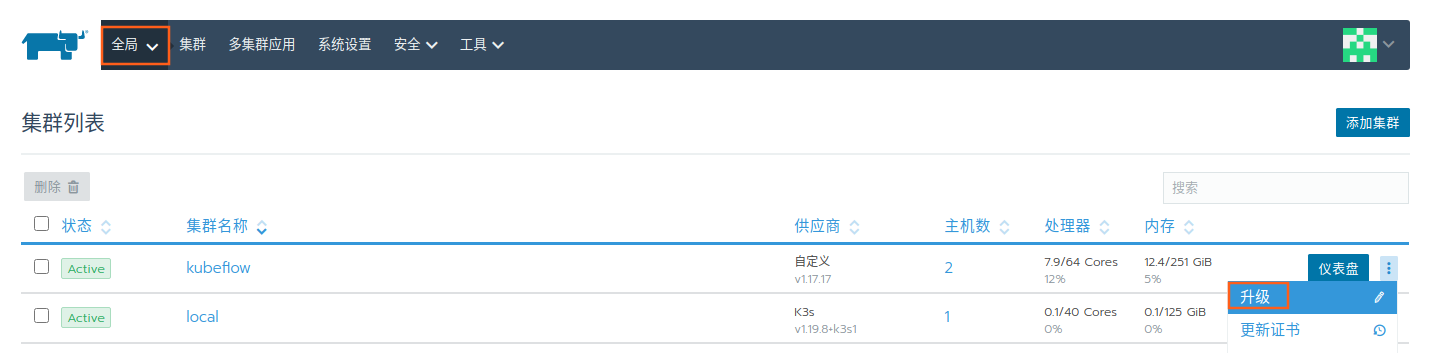
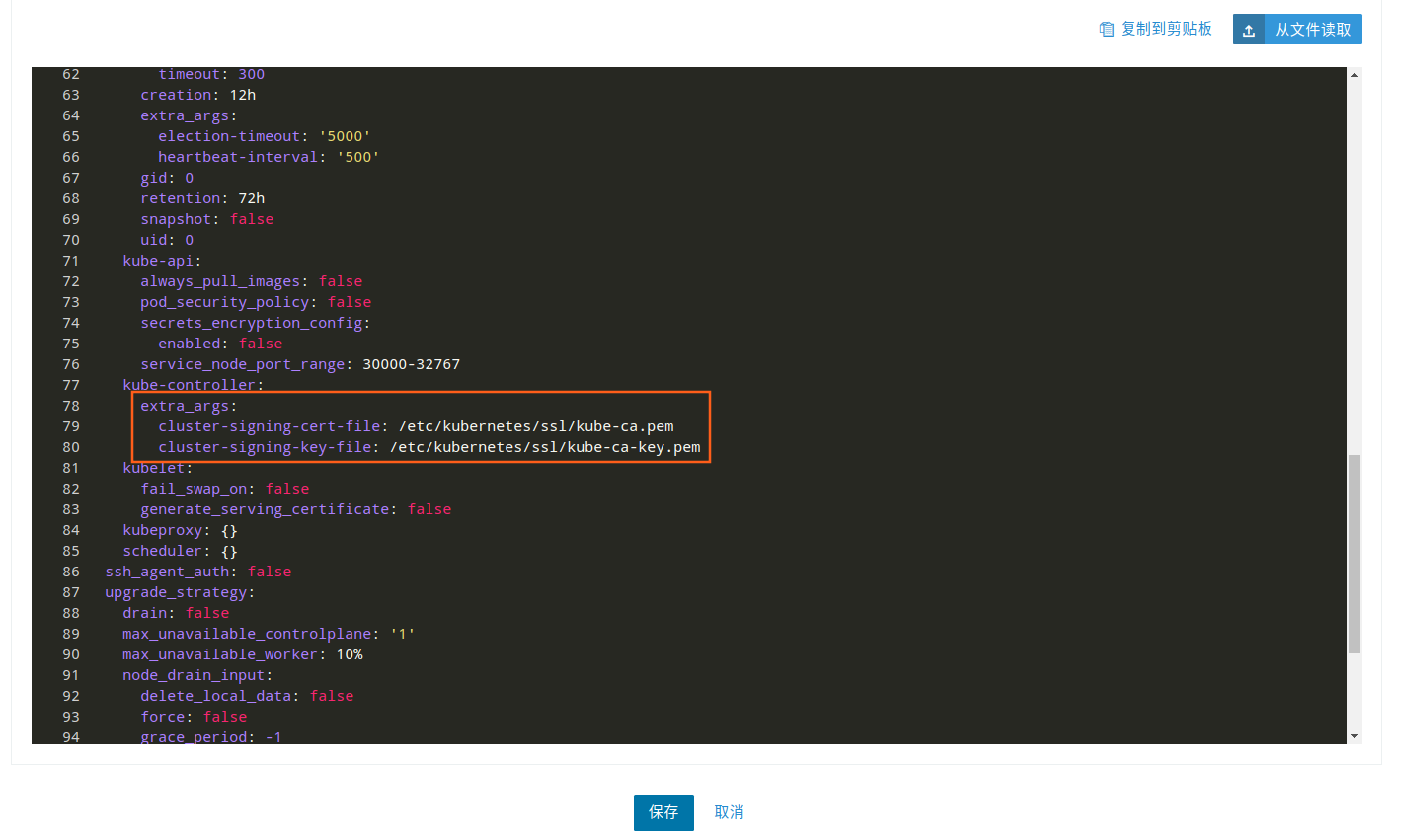
在全局页面,点击升级
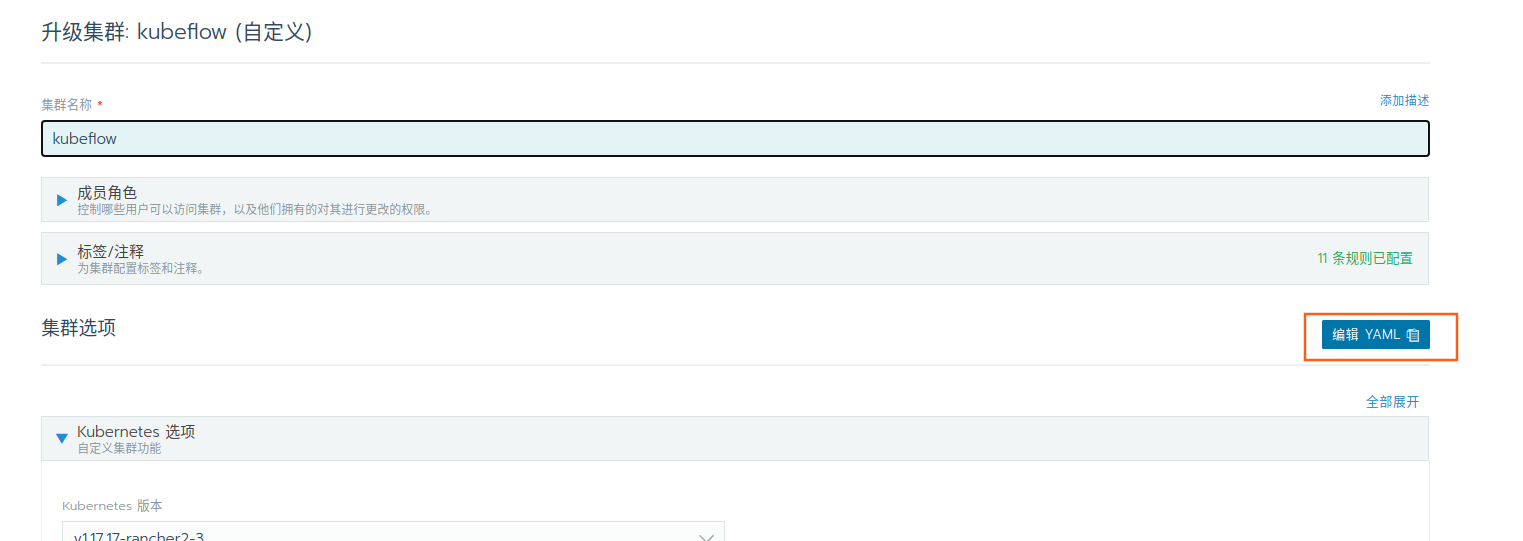
选择编辑YAML文件
在 kube-controller 字段下添加如下 3 行
extra_args: cluster-signing-cert-file: "/etc/kubernetes/ssl/kube-ca.pem" cluster-signing-key-file: "/etc/kubernetes/ssl/kube-ca-key.pem"
Kubeflow 的安装要求比较苛刻,前面的大部分操作都是为了 Kubeflow 铺路,官方指定的方式适合在墙外操作,由于各种原因墙内操作几乎不太容易实现,所以经摸索,选出了一条合适的方法。
https://github.com/shikanon/kubeflow-manifests
这是一份长期更新的国内镜像版本的 Kubeflow 安装文件,不用管 README.md 是如何描述的,只要上述步骤没问题,克隆下来,
git clone https://github.com/shikanon/kubeflow-manifests.git --depth 1
直接 python install.py,即可。
如果安装过程中的输出没有报错出现的话,可以通过以下命令监控后续的各 pods 创建的状态和进度:
$ kubectl get pods -A
如果所有的 pods 都进入 Running 或 Completed 状态,那么就说明部署成功了,如果有节点迟迟卡在创建状态,可以重新执行一遍 python install.py
如果要删除,可以执行
$ kubectl delete -f manifest1.3
在 Rancher 页面,可能看不见这些 pods
是因为他们没有被归到某一个 project 下面,点击集群名称,点击命名空间,即可看见,将之挪到 Default 项目或新建项目下,即可在对应项目下看到这些 pods 的命名空间及 pods 详情了。
默认用户名密码不正确/如何添加新的用户和命名空间
可以编辑 patch/auth.yaml 文件,在
staticPasswords: - email: "admin@example.com" hash: "$2y$12$X.oNHMsIfRSq35eRfiTYV.dPIYlWyPDRRc1.JVp0f3c.YqqJNW4uK" username: "admin" userID: "08a8684b-db88-4b73-90a9-3cd1661f5466" - email: myname@abc.cn hash: $2b$10$.zSuIlx1bl9PCyigEtebhuWG/PAhZlZoyokPdGObiE7jRUHUcQ0qW username: myname userID: 08a8684b-db88-4b73-90a9-3cd1661f5466
可以添加用户,密码使用 hash 生成,可以通过 https://passwordhashing.com/BCrypt 工具来生成密码。
注意:每一个用户都对应了一个命名空间(namespace),所以如果添加了新用户,需要对应的添加新的命名空间,在此文件的下面几行
--- apiVersion: kubeflow.org/v1beta1 kind: Profile metadata: name: kubeflow-user-example-com spec: owner: kind: User name: admin@example.com
最后,重新
或者直接使用此命令编辑容器配置,保存后自动应用。
kubectl edit configmap dex -n auth
当 Kubeflow 服务启动完成后,可以通过
$ kubectl port-forward svc/istio-ingressgateway -n istio-system 8080:80
将容器内网关的 80 端口临时暴露到本机的 8080 端口,通过 localhost 域名以 http 的方式访问。
通过修改 patch/auth.yaml 文件,可以更改密码,默认的用户名是admin@example.com,密码是password。
生成密码的方式是
python3 -c 'from passlib.hash import bcrypt; import getpass; print(bcrypt.using(rounds=12, ident="2y").hash(getpass.getpass()))'
或通过 https://passwordhashing.com/BCrypt 在线工具。
如果要通过 NodePort / LoadBalancer / Ingress 暴露服务到非 localhost 网络,那么必须使用 https。否则能打开主页面但是 notebook、ssh等均无法连接。
一个简单可行的方案是使用 NodePort 。
使用如下命令:
$ kubectl -n istio-system get service istio-ingressgateway
可以发现,443 端口被映射到物理机的 32692,但是此时 443 端口还没有启用服务,下面几步将生成并启用证书,以启动 443 端口。
使用前文中提到过的脚本,生成新的ssl证书,供给 kubeflow 使用。
./create_self-signed-cert.sh --ssl-domain=kub**a.cn
如果有CA签名的证书亦可直接使用。
kubectl create --namespace istio-system secret tls kf-tls-cert --key /data/gang/kfcerts/kub***a.cn.key --cert /data/gang/kfcerts/kub***a.cn.crt
kubectl edit cm config-domain --namespace knative-serving
在 data 下面添加一个名为域名的键,值若无特殊需求的话可以留空,如:kub***a.cn: ""
编辑 manifest1.3/016-istio-1-9-0-kubeflow-istio-resources-base.yaml 文件
vim manifest1.3/016-istio-1-9-0-kubeflow-istio-resources-base.yaml
在最后面的 kubeflow-gateway 中,添加
- hosts: - '*' port: name: https number: 443 protocol: HTTPS tls: mode: SIMPLE credentialName: kf-tls-cert
hosts 可以直接指定为刚刚生成的证书所绑定的域名(仅接受此域名的访问),也可以填写成 * 以接受其他域名的访问。
kubectl apply -f manifest1.3/016-istio-1-9-0-kubeflow-istio-resources-base.yaml
这样就能在其他机器上通过
curl https://10.1***2:32692 -k
安全的访问到 Kubeflow 服务了。由于是自签名证书,所以使用-k 参数可以绕过检查。
谨慎使用脚本,删除残留文件、服务、网络配置、容器等 !
#!/bin/bash ' kubelet kube-scheduler kube-proxy kube-controller-manager kube-apiserver ' for kube_svc in ${KUBE_SVC} ;do if [[ `systemctl is-active ${kube_svc} ` == 'active' ]]; then ${kube_svc} fi if [[ `systemctl is-enabled ${kube_svc} ` == 'enabled' ]]; then disable ${kube_svc} fi done for mount in $(mount | grep tmpfs | grep '/var/lib/kubelet' | awk '{ print $3 }' ) /var/lib/kubelet /var/lib/rancher;do $mount ;done "%Y%m%d%H%M" )"%Y%m%d%H%M" )"%Y%m%d%H%M" )"%Y%m%d%H%M" )log /containers \log /kube-audit \log /pods \' lo docker0 eth ens bond ' for net_inter in $network_interface ;do if ! echo "${no_del_net_inter} " | grep -qE ${net_inter:0:3} ; then $net_inter fi done ' 80 443 6443 2376 2379 2380 8472 9099 10250 10254 ' for port in $port_list ;do $port | awk '{print $7}' | awk -F '/' '{print $1}' | grep -v - | sort -rnk2 | uniq`if [[ -n $pid ]]; then kill -9 $pid fi done '{print $2}' `if [[ -n $kube_pid ]]; then kill -9 $kube_pid fi
另外,创建 Rancher 的时候指定的几个卷文件夹,也可以酌情删除
rm -rf /data/var/log /rancher/auditlog
自定义镜像必须要达到几个要求,才能通过 kubeflow 正确访问,参考
tensorflow 与 cuda 对应关系如下表
版本
Python 版本
cuDNN
CUDA
tensorflow-2.6.0
3.6-3.9
8.1
11.2
tensorflow-2.5.0
3.6-3.9
8.1
11.2
tensorflow-2.4.0
3.6-3.8
8.0
11.0
tensorflow-2.3.0
3.5-3.8
7.6
10.1
tensorflow-2.2.0
3.5-3.8
7.6
10.1
tensorflow-2.1.0
2.7、3.5-3.7
7.6
10.1
tensorflow-2.0.0
2.7、3.3-3.7
7.4
10.0
tensorflow_gpu-1.15.0
2.7、3.3-3.7
7.4
10.0
tensorflow_gpu-1.14.0
2.7、3.3-3.7
7.4
10.0
tensorflow_gpu-1.13.1
2.7、3.3-3.7
7.4
10.0
tensorflow_gpu-1.12.0
2.7、3.3-3.6
7
9
tensorflow_gpu-1.11.0
2.7、3.3-3.6
7
9
tensorflow_gpu-1.10.0
2.7、3.3-3.6
7
9
tensorflow_gpu-1.9.0
2.7、3.3-3.6
7
9
tensorflow_gpu-1.8.0
2.7、3.3-3.6
7
9
tensorflow_gpu-1.7.0
2.7、3.3-3.6
7
9
tensorflow_gpu-1.6.0
2.7、3.3-3.6
7
9
tensorflow_gpu-1.5.0
2.7、3.3-3.6
7
9
tensorflow_gpu-1.4.0
2.7、3.3-3.6
6
8
tensorflow_gpu-1.3.0
2.7、3.3-3.6
6
8
tensorflow_gpu-1.2.0
2.7、3.3-3.6
5.1
8
tensorflow_gpu-1.1.0
2.7、3.3-3.6
5.1
8
tensorflow_gpu-1.0.0
2.7、3.3-3.6
5.1
8
创建 Dockerfile 文件:
以下内容可以任意更改,以符合需求,或者等实例化容器后,进入 bash 手动添加更多功能也可。
FROM nvidia/cuda:10.0 -cudnn7-runtime-ubuntu18.04 as baseRUN apt-get update && apt-get install -y --no-install-recommends \ build-essential \ curl \ unzip ENV LANG C.UTF-8 RUN apt-get update && apt-get install -y \ python3 \ python3-pip RUN python3 -m pip --no-cache-dir install --upgrade \ "pip<20.3" \ setuptools RUN ln -s $(which python3) /usr/local /bin/python ARG TF_PACKAGE=tensorflow-gpuARG TF_PACKAGE_VERSION=1.15 .5 RUN python3 -m pip install --no-cache-dir ${TF_PACKAGE} ${TF_PACKAGE_VERSION:+==${TF_PACKAGE_VERSION} } RUN python3 -m pip install --no-cache-dir jupyter matplotlib RUN python3 -m pip install --no-cache-dir jupyter_http_over_ws ipykernel==5.1.1 nbformat==4.4.0 RUN jupyter serverextension enable --py jupyter_http_over_ws RUN mkdir -p /home/jovyan && chmod -R a+rwx /home/jovyan RUN mkdir /.local && chmod a+rwx /.local RUN apt-get update && apt-get install -y --no-install-recommends wget git RUN apt-get autoremove -y WORKDIR /home/jovyan EXPOSE 8888 RUN python3 -m ipykernel.kernelspec ENV NB_PREFIX /CMD ["bash" , "-c" , "source /etc/bash.bashrc && jupyter notebook --notebook-dir=/home/jovyan --ip 0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX} " ]
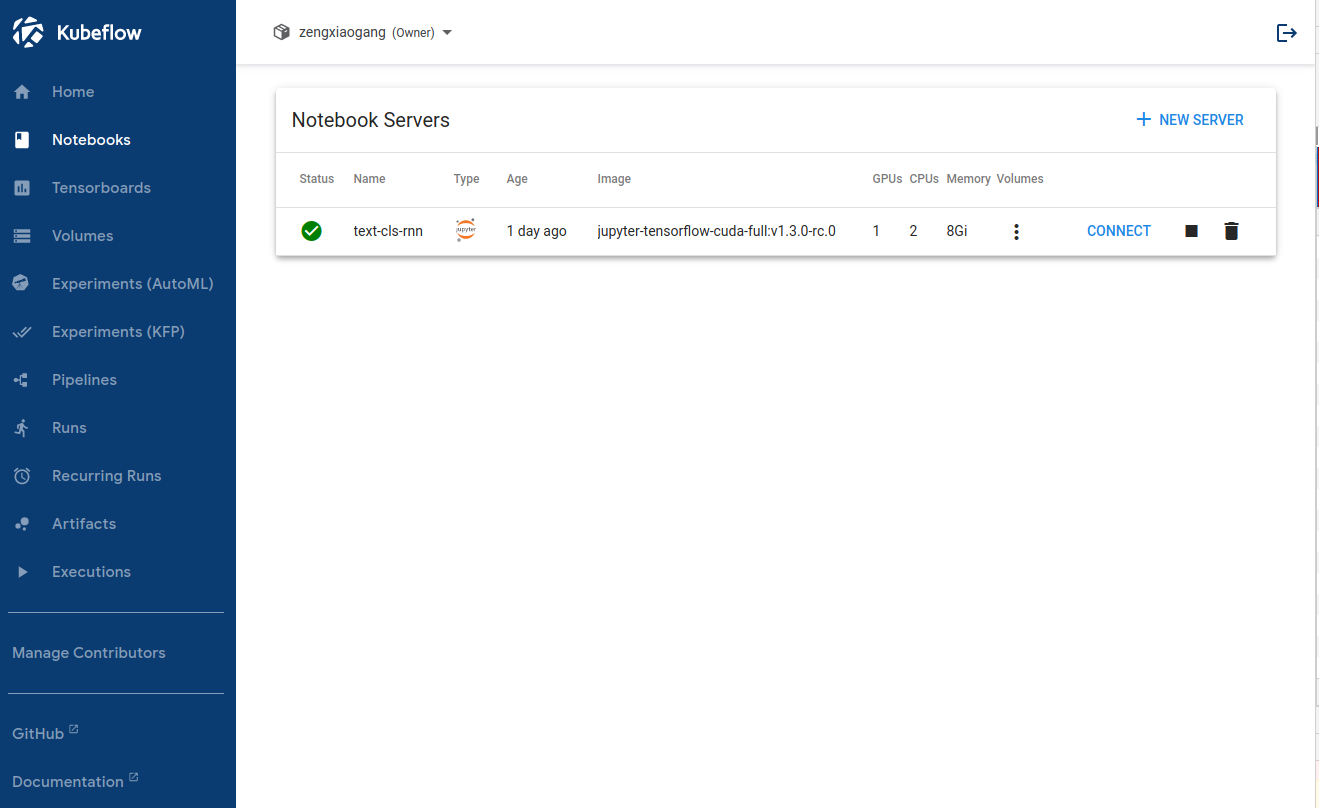
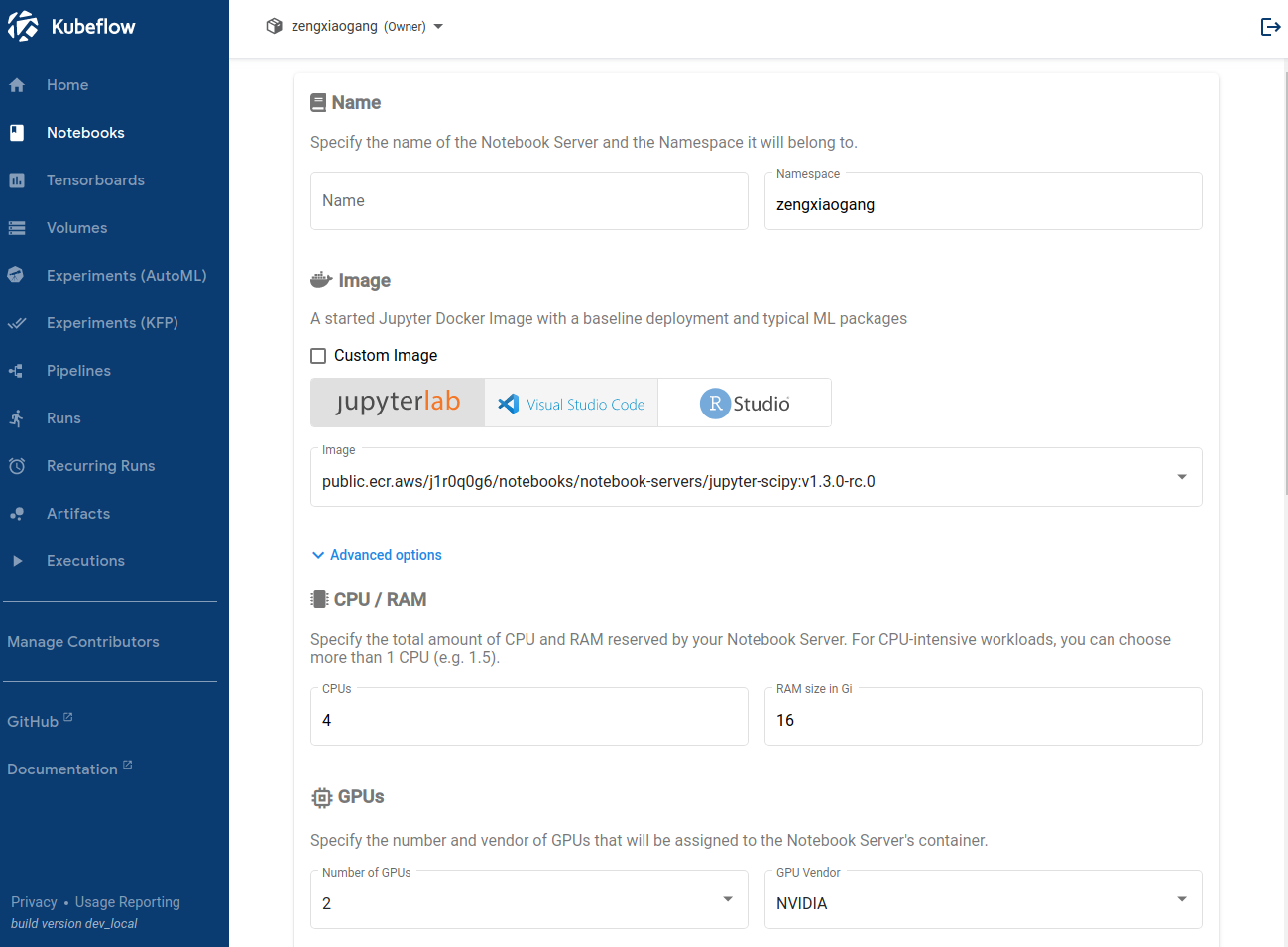
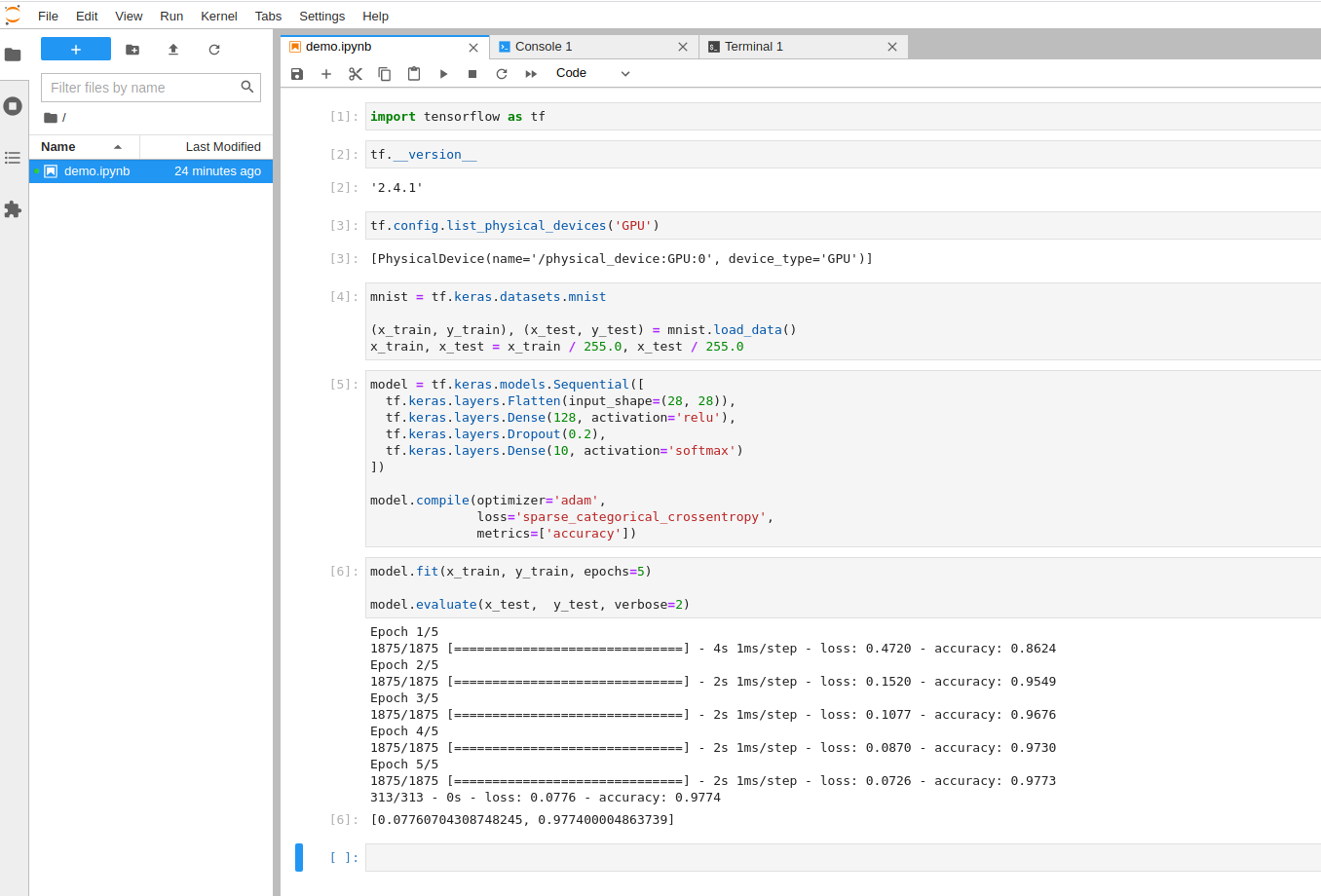
将其构建成镜像,托管到 docker hub 上,然后在 Kubeflow 上创建 Jupyter server 时,选择 Custom image,填入自己构建的镜像,即可创建成功,打开测试可以看见 gpu 可用。

pytorch 与 cuda 对应的关系如下表
CUDAToolkit版本
可用PyTorch版本
7.5
0.4.1 ,0.3.0, 0.2.0,0.1.12-0.1.6
8.0
1.1.0,1.0.0 ,0.4.1
9.0
1.1.0,1.0.1, 1.0.0,0.4.1
9.2
1.7.1,1.7.0,1.6.0,1.5.1,1.5.0,1.4.0,1.2.0,0.4.1
10.0
1.2.0,1.1.0,1.0.1 ,1.0.0
10.1
1.7.1,1.7.0,1.6.0,1.5.1,1.5.0, 1.4.0,1.3.0
10.2
1.7.1,1.7.0,1.6.0,1.5.1,1.5.0
11.0
1.7.1,1.7.0
11.1
1.8.0
创建 Dockerfile 文件:
以下内容可以任意更改,以符合需求,或者等实例化容器后,进入 bash 手动添加更多功能也可。
FROM nvidia/cuda:10.2 -cudnn7-runtime-ubuntu18.04 as baseRUN apt-get update && apt-get install -y --no-install-recommends \ build-essential \ curl \ unzip ENV LANG C.UTF-8 RUN apt-get update && apt-get install -y \ python3 \ python3-pip RUN python3 -m pip --no-cache-dir install --upgrade \ "pip<20.3" \ setuptools RUN ln -s $(which python3) /usr/local /bin/python RUN python3 -m pip install --no-cache-dir torch==1.8.0 RUN python3 -m pip install --no-cache-dir jupyter matplotlib RUN python3 -m pip install --no-cache-dir jupyter_http_over_ws ipykernel==5.1.1 nbformat==4.4.0 RUN jupyter serverextension enable --py jupyter_http_over_ws RUN mkdir -p /home/jovyan && chmod -R a+rwx /home/jovyan RUN mkdir /.local && chmod a+rwx /.local RUN apt-get update && apt-get install -y --no-install-recommends wget git RUN apt-get autoremove -y WORKDIR /home/jovyan EXPOSE 8888 RUN python3 -m ipykernel.kernelspec ENV NB_PREFIX /CMD ["bash" , "-c" , "source /etc/bash.bashrc && jupyter notebook --notebook-dir=/home/jovyan --ip 0.0.0.0 --no-browser --allow-root --port=8888 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' --NotebookApp.base_url=${NB_PREFIX} " ]
将其构建成镜像,托管到 docker hub 上,然后在 Kubeflow 上创建 Jupyter server 时,选择 Custom image,填入自己构建的镜像,即可创建成功,打开测试可以看见 gpu 可用。
编辑 manifest1.3/022-jupyter-overlays-istio.yaml 文件:
$ vim manifest1.3/022-jupyter-overlays-istio.yaml
在 data -> spawnerFormDefaults -> image -> options 里面添加自己创建的适用于 kubeflow 的镜像,如:
spawnerFormDefaults: image: value: public.ecr.aws/j1r0q0g6/notebooks/notebook-servers/jupyter-scipy:v1.3.0 options: - public.ecr.aws/j1r0q0g6/notebooks/notebook-servers/jupyter-scipy:v1.3.0 - public.ecr.aws/j1r0q0g6/notebooks/notebook-servers/jupyter-pytorch-full:v1.3.0 - public.ecr.aws/j1r0q0g6/notebooks/notebook-servers/jupyter-pytorch-cuda-full:v1.3.0 - harbordocker/kf-pt:1.2.0-gpu-jupyter-cuda100 - harbordocker/kf-pt:1.4.0-gpu-jupyter-cuda101 - harbordocker/kf-pt:1.5.1-gpu-jupyter-cuda102 - harbordocker/kf-pt:1.6.0-gpu-jupyter-cuda102 - harbordocker/kf-pt:1.7.1-gpu-jupyter-cuda102 - harbordocker/kf-pt:1.8.0-gpu-jupyter-cuda102 - harbordocker/kf-pt:1.8.1-gpu-jupyter-cuda102 - harbordocker/kf-pt:1.8.1-gpu-jupyter-cuda111 - public.ecr.aws/j1r0q0g6/notebooks/notebook-servers/jupyter-tensorflow-full:v1.3.0 - public.ecr.aws/j1r0q0g6/notebooks/notebook-servers/jupyter-tensorflow-cuda-full:v1.3.0 - harbordocker/kf-tf:1.13.2-gpu-jupyter-cuda100 - harbordocker/kf-tf:1.14.0-gpu-jupyter-cuda100 - harbordocker/kf-tf:1.15.5-gpu-jupyter-cuda100 - harbordocker/kf-tf:2.0.4-gpu-jupyter-cuda100 - harbordocker/kf-tf:2.1.3-gpu-jupyter-cuda101 - harbordocker/kf-tf:2.2.2-gpu-jupyter-cuda101 - harbordocker/kf-tf:2.3.2-gpu-jupyter-cuda101 - harbordocker/kf-tf:2.4.1-gpu-jupyter-cuda110 - harbordocker/kf-tf:2.5.0-gpu-jupyter-cuda112
完事儿再重新应用一下就可以在页面上看见了
$ kubectl apply -f manifest1.3/022-jupyter-overlays-istio.yaml