
没有关系。
本文目的
本文的目的是带领您走进 Spark 的世界,认识到一些基本概念,包括:
- Hadoop 的 MapReduce、YARN和HDFS等基本概念
- Hadoop 的不足
- Spark 是什么
- Spark 和 Hadoop 共存还是互斥?
- Spark 的血缘关系
认识到这个世界的神奇,了解 Spark 都能做什么事情。
前言
Spark 和 Hadoop 都是大数据处理工具,大数据的处理,往往伴随着数据的存储,数据的读取,数据的变形(又叫预处理),还可能会有数据训练,最终都会有数据输出。
接下来几个章节,我将向您介绍现有的一些技术框架都是为了解决什么问题提出来的,还有他们解决问题的原理是怎样的。
MapReduce
Hadoop 年龄比较大,是大数据分析刚刚兴起时,提出了一种基于 MapReduce 的技术手段。
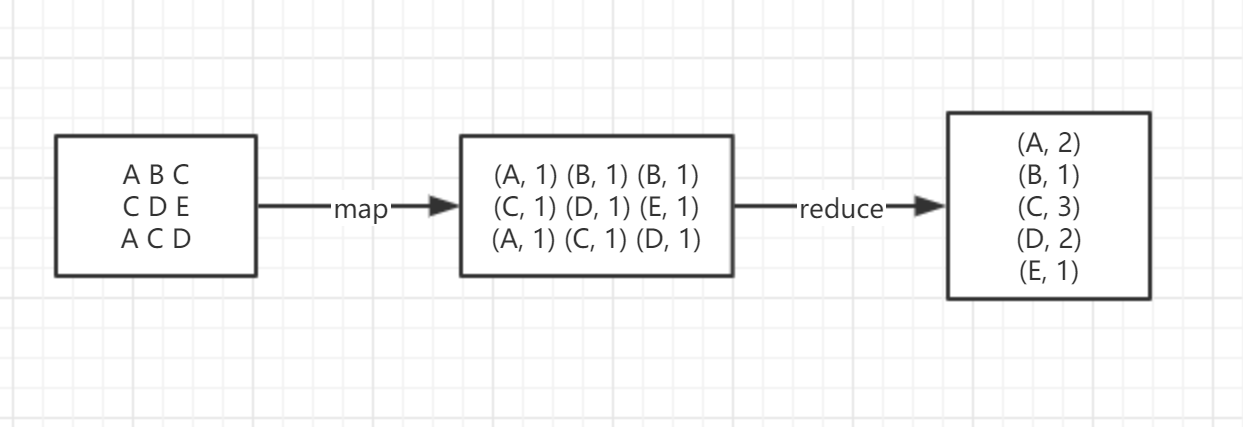
类似上图的例子,数据在 map 阶段,每个数据都有一次变形的机会,比如 A 变成 (A, 1) 这样的,也可以做任意的其他变形(取决于代码是怎么写的了);然后在 reduce 的时候,数据之间有一次相互计算的机会,比如图中是通过左边的值作为 key 进行的右边值加和计算,也叫作 reduceByKey ,其中的方式是加和,当然也可以做任意的其他计算(取决于代码是怎么写的了)。
这样就完成了一篇文章里的 WordCount。
通过上面这个例子,想必您也明白了 Hadoop 提出的 MapReduce 的技术手段的含义,他的重要性,在于其提出了一个里程碑式的思想。
HDFS、YARN
同时,宏观上讲 Hadoop 其本身,也是专为大数据设计的一套平台,包含很多模块,除了 MapReduce ,还有著名的分布式文件存储 HDFS(Hadoop Distributed File System),节点之间的分布式资源调度管理器 YARN(Yet Another Resource Negotiator)

上图是 YARN 管理节点的示意图[1],其中 Resource Manager 作为重要的节点,执行调度资源的任务。就像老板安排工作一样,A节点执行失败了,就会重新交给其他节点去做,然后尝试重启 A 节点,交给他其他任务,当然节点之间也是可以相互通信,交换数据的(取决于代码怎么写)。
当然还有很多很多其他和 Hadoop 同时期的组件或模块被提出来,辅助大数据的处理,存储,分发及应用。这里就不再一一罗列了。
Hadoop的局限和不足[2]
MapRecue 存在以下局限,使用起来比较困难。
- 抽象层次低,需要手工编写代码来完成,使用上难以上手
- 只提供两个操作,Map和Reduce,表达力欠缺
- 一个Job只有Map和Reduce两个阶段(Phase),复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的
- 处理逻辑隐藏在代码细节中,没有整体逻辑
- 中间结果也放在HDFS文件系统中
- ReduceTask 需要等待所有 MapTask 都完成后才可以开始
- 时延高,只适用 Batch 数据处理,对于交互式数据处理,实时数据处理的支持不够
- 对于迭代式数据处理性能(也就是机器学习算法)比较差
Spark 的出现
在 Hadoop 年代,尽管涌现出了一波组件框架来支持 Hadoop,让他发展的更好,比如列式数据库 HBase,Hive SQL 数据处理等等,但是由于 Hadoop MapReduce 其原理的关系,数据量太大,MapReduce 的性能就变得不尽人意。
这时候 Spark 横空出世,一篇 paper:Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[3] 介绍了 RDD 概念,RDD 通过他灵活又不失结构的特性,为 Spark 赢得了一席之地。
Spark 的数据处理流程也是分布式的,而且是内存型的,中间结果数据可以放在内存里,再次访问到时处理特别快。
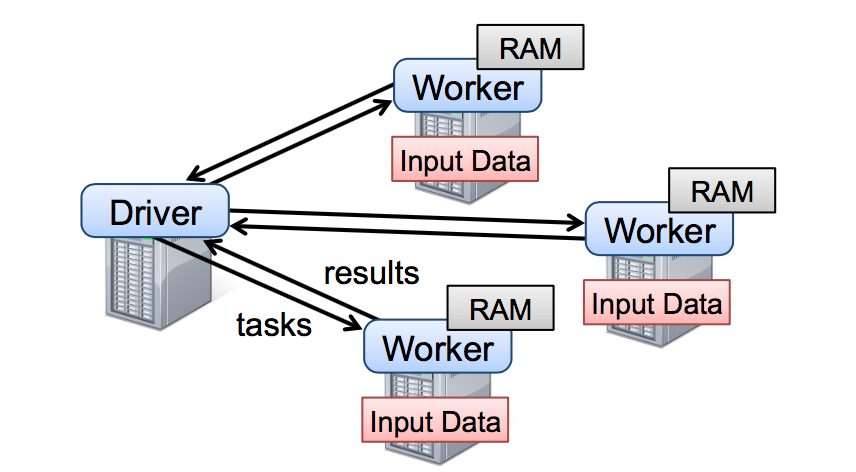
如上图所示:Spark 启动一个分布式项目,通过一些参数指定,driver 的内存大小、Worker 的内存大小,CPU 核心数等信息,至于机器节点之间的通信和资源管理,可以依赖 Hadoop YARN 、Mesos 或 Kubernetes。
Spark Driver & Worker
Spark 在运行一个项目的时候,机器被分为 Driver 和 Worker,就像 Master 和 Slave 一样,Driver 节点处理不能单独在 Worker 节点完成计算的数据,比如“将所有数据拼接起来输出”这样的需求,Worker 节点通过读取分布式数据存储系统上面的数据,各自进行计算,如果有需要的话(取决于代码怎么写),会把计算好的数据发到 Driver 节点,进行进一步处理,当然节点之间也是可以通信的,但是仍然需要接受 Driver 的调度。
不管是 Driver 节点,还是 Worker 节点,他们可以需要一个后台来调度,让其支持分布式,可以是 Hadoop YARN 、Mesos 或 Kubernetes。但是,Local 模式和 Standalone 模式下运行的 Spark 是不需要的,其中 Standalone 模式运行是 Spark 自身充当资源调度。
注意我在上文中提到的概念:节点。之所以我一直在说节点,是因为一台机器可以被资源管理器统一虚拟化,比如一台物理机是64G内存,我们创建一个 Driver 节点,内存4G,2个 Workers 节点,每个内存5G,那么总共3个节点消耗这台机器$ 4G_{driver} + 2\times 5G_{Worker}=14G $ 内存,CPU 核心数的分配也是同理。
RDD
Spark 1.x 时代的产物。如果您看到下面这样的创建 spark 上下文,连接至 driver 节点的方式,那就说明是 rdd 为主的代码。
|
|
|
DataFrame
新时代下的产物,相比 RDD 来,速度更快,API设计更加现代化,思维逻辑更加合理。如果您看到下面这样的创建 spark 会话,连接至 driver 节点的方式,那就说明是 dataframe 为主的代码。
|
|
|
通常情况下,我们用
sc代表 spark 上下文,spark代表 spark 会话,local代表以 local 模式启动,[*]代表使用本机器所有CPU线程启动,也可以换成特定的数字,比如[2]代表两个CPU线程启动。这里所指的线程,是指类似“四核八线程”这样的可以并行的线程数。
通常情况下,我们也应该选择 Dataframe 而不是 RDD。
spark 里面的通用概念
Transformations
Spark 里面最重要的两个概念其中一个是 transformation ,这也是 Spark 的核心概念。
其中 transformation 代表对数据的变形,类似我们上面提到的 MapReduce,比如常见的:
map():就像 MapReduce 里面的map一样,对每一个数据都进行重整形filter():按照一定的条件过滤数据,等同于 SQL 里的wheregroupbyKey():按照数据子项中左边的 key 对数据进行分组,类似 SQL 里面的group by xxxreducebyKey():就像 MapReduce 里面的reduce一样,数据之间相互计算
transformation 的特性是 lazy 的,代码执行完,并不会对数据进行任何操作,他只是在构建任务策略,任务策略也是持续性变化的,比如后面再有 transformation,可能 Spark 认为可以将两个任务优化一下,所以任务策略是会发生变化的。只有在遇到 action 的时候,数据才被前面定义的那些 transformation 来处理。
Actions
Spark 里面另外一个重要概念是 action ,这也是 Spark 的核心概念。
Action 代表要对数据执行动作,比如输出,或者查看数据,常见的:
-
show(): 展示数据的内容 -
count(): 计算数据的个数 -
take(): 拿数据的前 n 行 -
first(): 拿数据的第一行 -
collect(): 把所有数据都集合到 driver 节点去,组成 List -
saveAsTextFile(): 保存成文本文件
当代码执行到这样的 actions 就会利用前面 transformation 生成的执行策略,去整形数据,再把数据应用这些 actions。
宽窄依赖
首先,声明一下,宽窄依赖是没有优劣之分的,都是非常重要的手段工具。
RDD 或 Dataframe 经过每一次的 transformation,都会生成新的 RDD 或 Dataframe,也就是说我们需要新的变量去接收,所以一系列 RDD 或 Dataframe 之间是有血缘关系(Lineage)的。
比如拿到文本之后(称为RDD1),将其 tokenize(称为RDD2),再去除停用词(称为RDD3),那么这三个RDD就是有血缘关系的,如果执行到RDD3时,前面的任务RDD2数据突然不幸丢失了,不会全部重新计算,而是直接从RDD1的基础上重新计算RDD2。
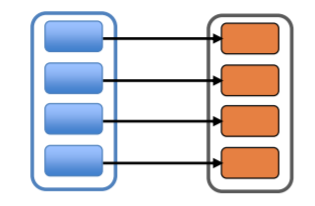
窄依赖是指,每个RDD最多只被一个RDD所依赖,比如各分区独立计算的 API:map, flatMap, filter, sample等。
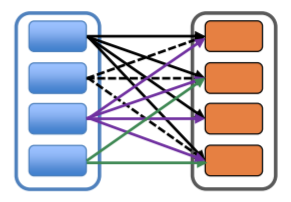
宽依赖是指,RDD会被多个RDD所依赖,比如需要各分区相互统筹协调计算的 API:distinct, join, repatition等。
显然,宽依赖中如果遇到分区丢失等数据问题,会导致数据大量的重新计算,而且这些操作,显然是需要各分区节点之间相互通信和交换数据的,也是计算速度缓慢的原因之一。但并不是说宽依赖的 API 就不能用了,合理使用,也是利刃。
Spark 组件模块[4]
整个 Spark 主要由以下模块组成:
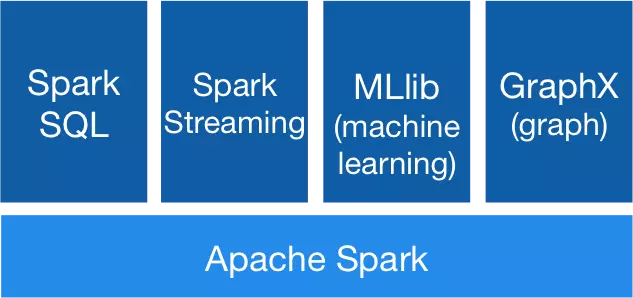
Spark Core(了解即可)
Spark的核心功能实现,包括:
-
SparkConf/SparkSession
SparkConf 用于管理Spark应用程序的各种会话配置信息。
-
Spark 内置 RPC 框架
Spark 内置 RPC 框架 使用 Netty 实现,有同步和异步的多种实现,Spark 各个组件间的通信都依赖于此 RPC 框架。
-
事件总线 ListenerBus
事件总线是 SparkContext 内部各个组件间使用事件——监听器模式异步调用的实现。
-
度量系统
度量系统由Spark中的多种度量源(Source)和多种度量输出(Sink)构成,完成对整个Spark集群中各个组件运行期状态的监控。
Spark SQL(写代码80%都是在写sql)
提供SQL处理能力,便于熟悉关系型数据库操作的工程师进行交互查询。此外,还为熟悉 Hive 开发的用户提供了对 Hive SQL 的支持。
Spark Streaming(实时数据的处理)
提供流式计算处理能力,目前支持 Apache Kafka、Apache Flume、Amazon Kinesis 和简单的 TCP 套接字等多种数据源。
此外,Spark Streaming 还提供窗口操作用于对一定周期内的流数据进行处理。
GraphX(图计算框架)
提供图计算处理能力,支持分布式,Pregel 和 AggregateMessage 提供的 API 可以解决图计算中的常见问题。
MLlib(常用的机器学习库)
Spark 提供的机器学习库。MLlib 提供了机器学习相关的统计、分类、回归、推荐等领域的多种算法实现。
其一致的 API 接口大大降低了用户的学习成本。
最佳实践
没有最佳实践,只有最适合您自己情况的实践。
以我目前的实践来讲,我使用 Spark + YARN + HDFS + HBase,来完成一系列的大数据处理工作,流程大概是:

下一篇文章,我们来讲解一下,如何搭建 Spark 基础(单机)开发环境。
参考文献
Apache Hadoop 3.2.1 – Apache Hadoop YARN[EB/OL]. [2020-01-09]. https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html. ↩︎
与 Hadoop 对比,如何看待 Spark 技术? - 知乎[EB/OL]. [2020-01-09]. https://www.zhihu.com/question/26568496. ↩︎
Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. USENIX Association, 2012: 2-2. ↩︎
【Spark】Spark 基本概念、模块和架构[EB/OL]. 简书, [2020-01-09]. https://www.jianshu.com/p/bd53509dc237. ↩︎




