
BERT (Bidirectional Encoder Representations from Transformers)
Bert 是 Transformer 的 Encoder 预训练模型,训练技巧是:预测文本中被遮挡的单词,预测两个句子是否是原文中相邻的句子。
预测文本中被遮挡的单词
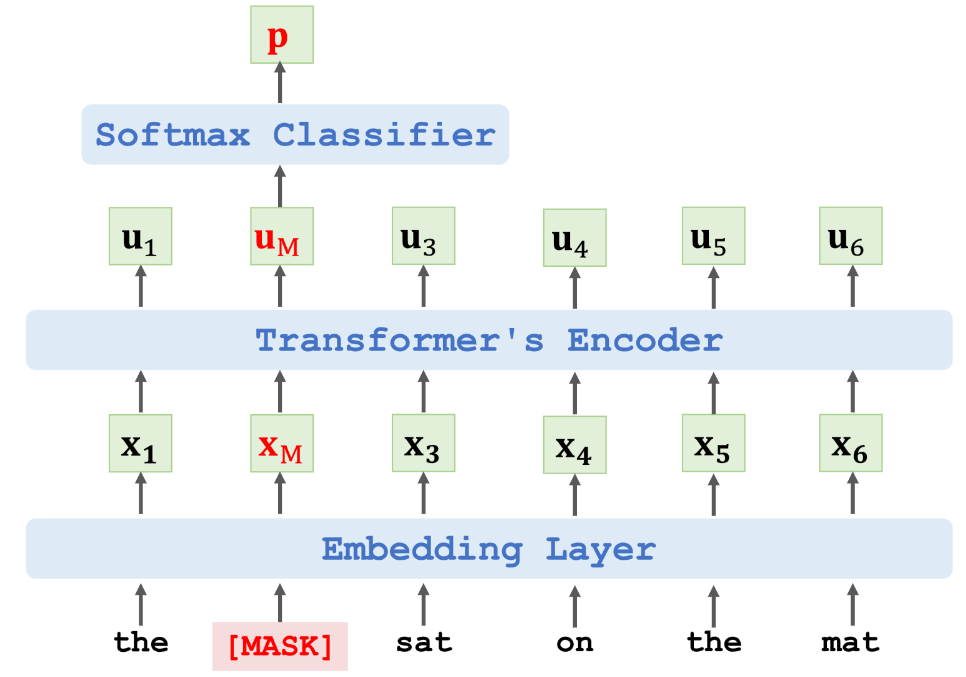
- :被遮挡单词 cat 的 one-hot 向量
- :被遮挡的地方输出的概率分布
- Loss = CrossEntropy(e, p)
- 执行梯度下降更新模型参数
预测两个句子是否是原文中相邻的句子
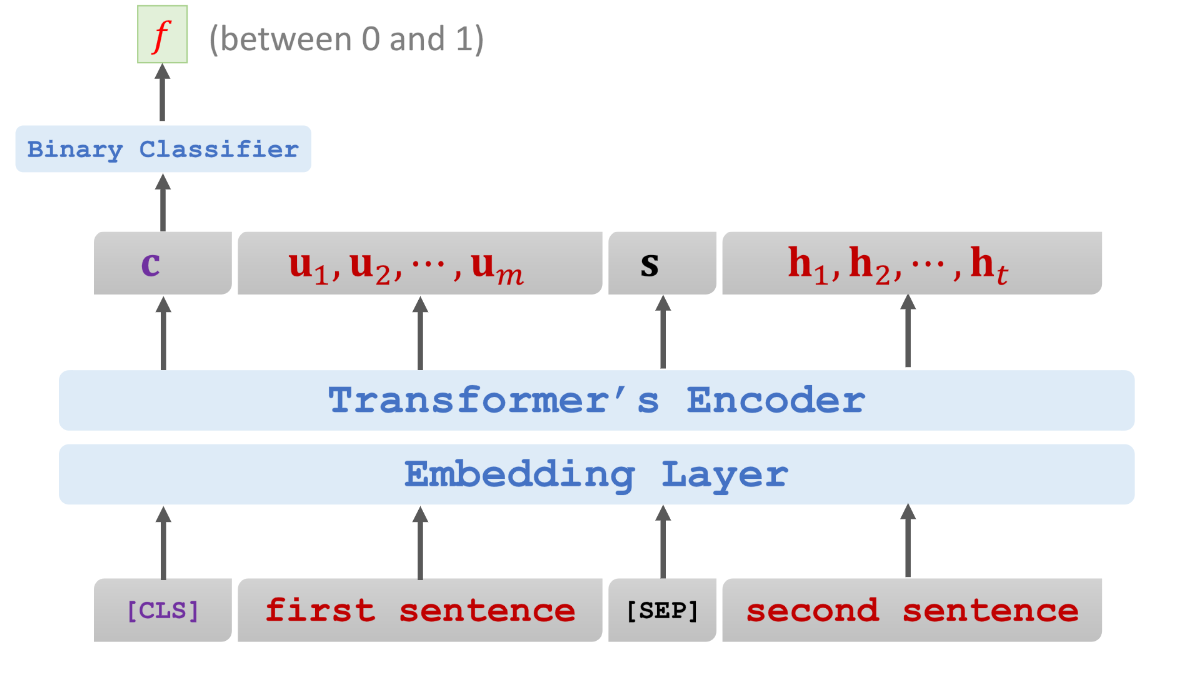
一个简单的分类任务
任务结合

将这两种任务结合到一起,使用大量数据来训练 bert 模型。
- BERT 不需要手工标数据
- 可使用大规模的数据集
- 随机遮挡单词
- 50% 的下一句是真的
- 参数太多,训练的代价也是巨大的




