- Transformer 是一种 Seq2Seq 模型
- Transformer 不是 RNN
- Transformer 只有 Attention 和 Dense 层
- Transformer 在 NLP 完爆其他模型
剥离 RNN,保留 Attention
Attention
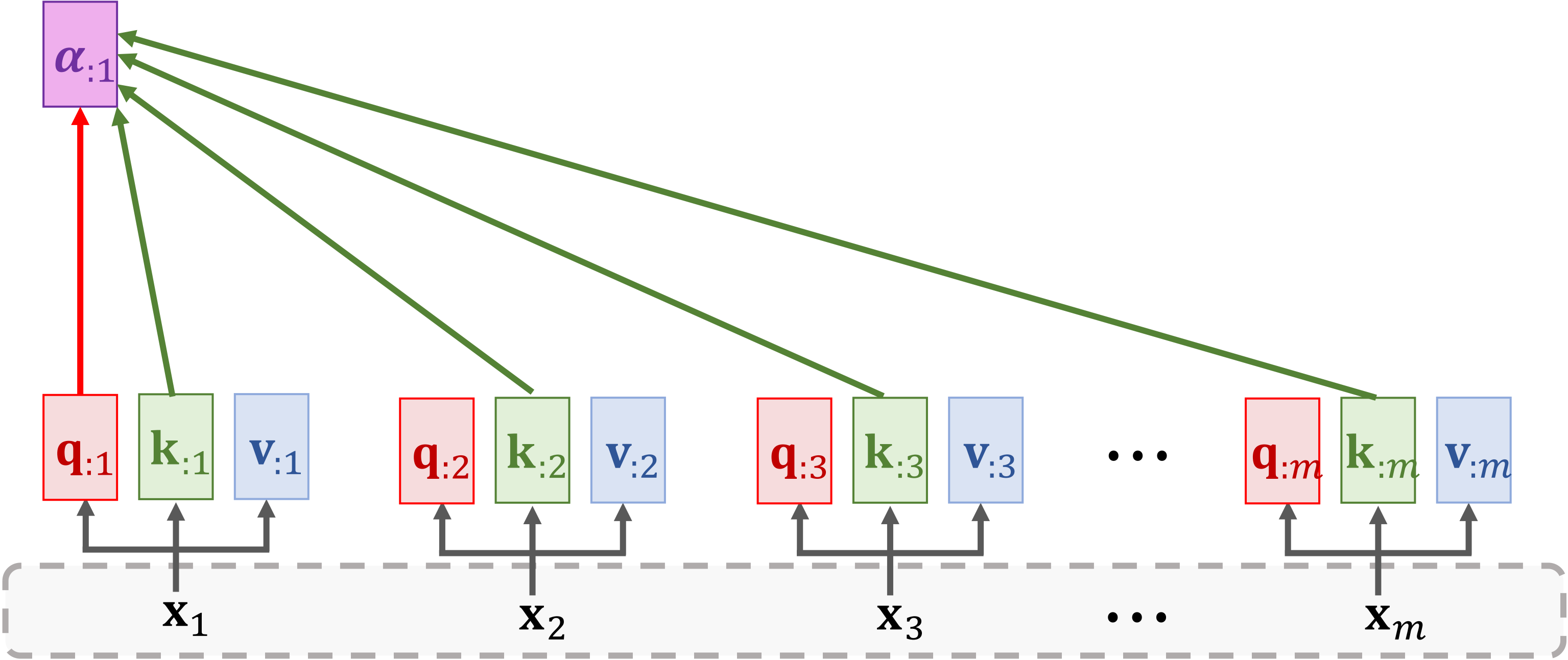
Encoder 端的输入 x1,x2,…,xm,经过映射生成 k:i 和 v:i
- Key: k:i=WKxi
- Value: v:i=WVxi

Decoder 端的输入 x1′,x2′,…,xt′,经过映射生成 q:j
- Query: q:i=WQxj′
计算权重向量 α:i:
α:i=Softmax(KTq:1)
计算上下文向量(Context Vector):
c:1=α11v:1+⋯+αm1v:m=Vα:1
直到所有 c 向量都计算完毕
c:j=α1jv:1+⋯+αmjv:m=Vα:j
上面公式又可写作:
c:j=Vα:j=V⋅softmax(KTq:j)=V⋅softmax((WKX)TWQxj′)
所以每个 c 向量都只和当前的 xj′ 与 所有的 xi 相关。
这就是 Attention:
C=Attn(X,X′)
- Encoder 的输入:X=[x1,x2,…,xm]
- Decoder 的输入:X′=[x1′,x2′,…,xt′]
- 参数矩阵:WQ,WK,WV
Self-Attention
对于 Self-Attention 来说,可用同一函数来处理,输入稍稍变一下即可
C=Attn(X,X)
- 输入:X=[x1,x2,…,xm]
- 参数矩阵:WQ,WK,WV
输入 x1,x2,…,xm,经过映射生成 q:i, k:i 和 v:i
- Query: q:i=WQxi
- Key: k:i=WKxi
- Value: v:i=WVxi
计算所有的 α:j 向量(α1,α2,…,αm)
α:j=Softmax(KTq:j)
计算所有的 c:j 向量(c1,c2,…,cm)
c:j=α1jv:1+⋯+αmjv:m=Vα:j
所有的 c 向量就是 Self-Attention 的输出
上面公式又可写作:
c:j=Vα:j=V⋅softmax(KTq:j)=V⋅softmax((WKX)TWQxj)
所以每个 c 向量都只和当前的 xj 与 所有的 xi 相关。
Multi-Head Self-Attention
单头自注意力可以被合并为多头自注意力,我愿称之为横向扩展
Stacked Self-Attention Layers
给每一个上下文向量后面都接一个 Dense 层,经过映射,再重新作为输入,接到到另一个 Self-Attention Layer。
我愿称之为纵向扩展。
Encoder
所以,以一个 Stacked Self-Attention Layers 作为 block。
6 个这样的 blocks 连在一起就叫做一个 Transformer 的 Encoder
Decoder
以前熟悉的 LSTM Encoder + Decoder (Seq2Seq)整体变成了一个 Decoder,叠了6 层的Encoder 输出的结果和目标文本经过多头 Self-Attention 的结果得到的上下文向量共同输入到多头 Attention 层,最终得到 z 向量,经过 Dense 层得到最终的输出 s
这样一个结构叫做一个 Decoder 的 block
将 6 个 Decoders 和 6 个 Encoders 连接在一起,就得到了一个 Transformer
总结
Encoder 总结:
- 1 encoder block ≈ multi-head self-attention + dense.
- Input shape: 512 × m.
- Output shape: 512 × m.
- Encoder network is a stack of 6 such blocks.
Decoder 总结:
- 1 decoder block ≈ multi-head self-attention + multi-head attention + dense.
- Input shape: (512 × m, 512 × t)
- Output shape: 512 × t.
- Decoder network is a stack of 6 such blocks.