
Spark 的运行环境
- spark 2.x 需要 JDK 8
- spark 3.0 需要 JDK 11
Spark 的运行模式
spark 有5中运行模式,Local,Standalone,Yarn,Mesos 和 Kubernetes。
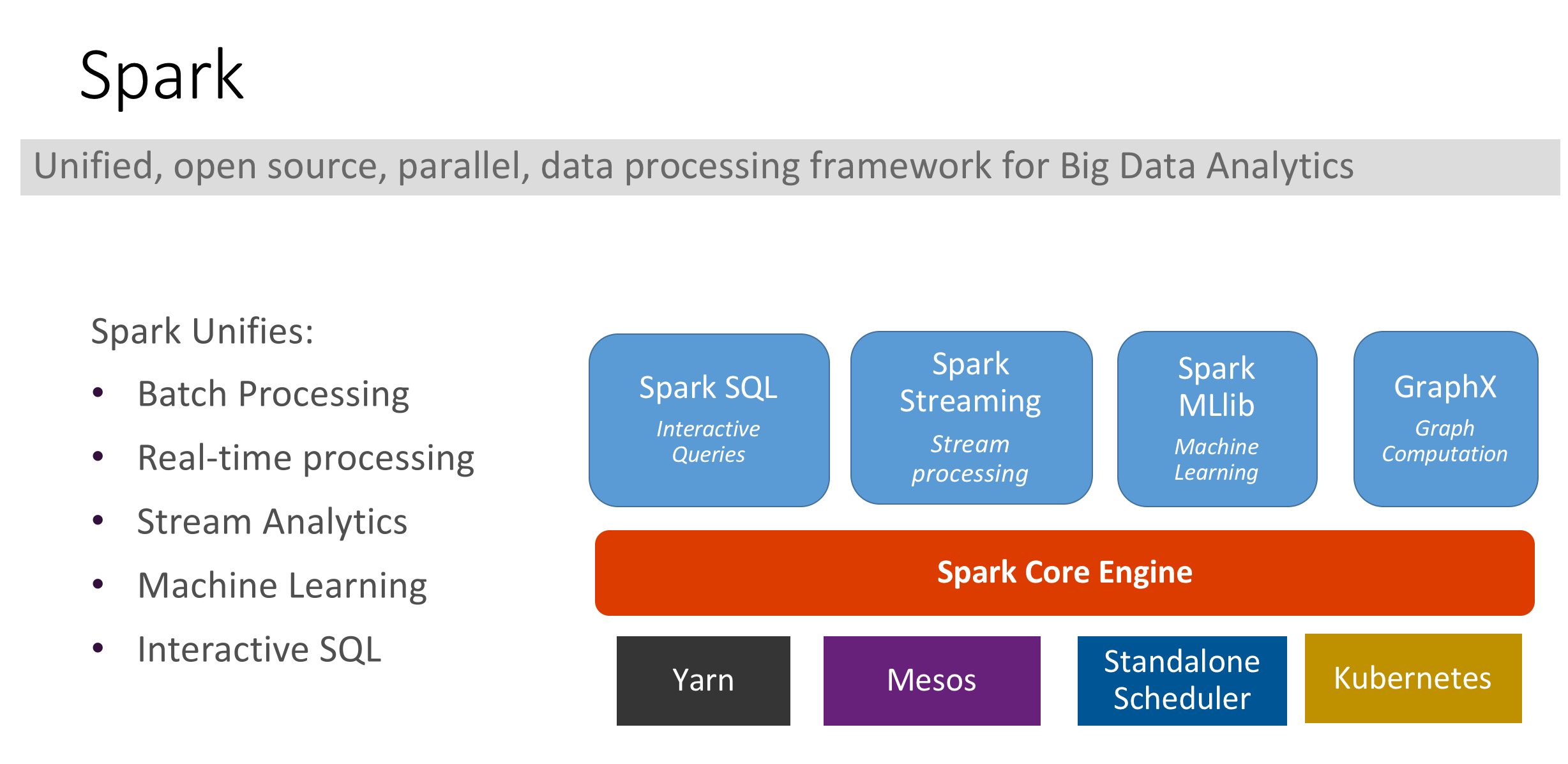
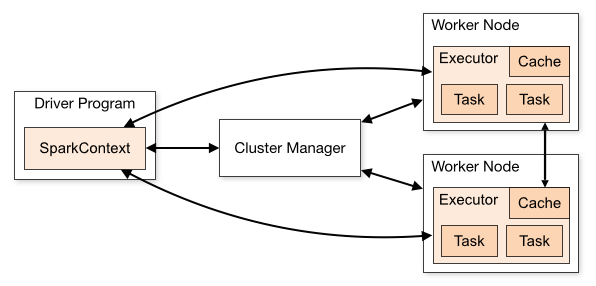
更加具体的来讲,下图[1]中的 Cluster Manager 可以是任意的集群资源管理框架,Spark 自身可以兼容多种 Cluster Manager,不同的 Cluster Manager 会表现出不同的性能,易操作性,稳定性,可扩展性等不同的优势,但是受限于现世的技术,磁盘IO一直是分布式资源调度和数据存取交换效率的瓶颈。
Local[2]
Local 模式即单机模式,也就是完全体会不到分布式的好处的一种模式。
如果在命令语句中不加任何配置,则默认是 Local 模式,在本地运行。
这也是最简单的一种模式,所有的 Spark 进程都运行在一台机器或一个虚拟机上面。
Standalone[2:1]
Standalone 是 Spark 自身实现的资源调度框架。如果我们只使用 Spark 进行大数据计算,不使用其他的计算框架(如MapReduce或者Storm)时,就采用 Standalone 模式就够了。
Standalone 模式是 Spark 实现的资源调度,其主要的节点有 Client 节点、Master 节点和 Worker 节点。其中 Driver 既可以运行在 Master 节点上中,也可以运行在本地 Client 端。
Client 节点是说启动 Spark 项目的节点,实际上可能同时是 Master 节点,也能可是 Worker 节点。
YARN
Yarn-Cluster,Yarn-Client 是 spark 应用的两种运行方式,他们都属于是在 YARN 的资管管理调度下运行的。
其中:
- cluster 模式提交应用,应用在集群中运行,提交之后,我们就失去了直接的对应用的控制权,比如查看打印出来的日志,终止掉应用等,如果想要做这些事情,只能去 YARN 的管理界面提供的界面上面去浏览日志,或管理应用的运行状态。
- client 模式提交应用,应用同样是在集群上运行,但是 driver 节点是在 client (客户端)运行,我们可以直接在提交的地方看见主要日志输出,按下 ctrl + c 或是关闭终端,任务就会被杀掉。
这两种模式没有优劣之分,均适合于生产环境上大规模机器群的应用提交。
Mesos
这种模式和 YARN 模式很像,只是把 YARN 做的工作替换成 Mesos 来完成。其中 Mesos 是出现更晚,更加先进的大规模集群资源管理框架。
Kubernetes
这种模式和 YARN 模式很像,只是把 YARN 做的工作替换成 Kubernetes 来完成。其中 Kubernetes 是出现比 Mesos 更晚,更加先进的大规模集群资源管理框架。而且 Kubernetes 更易与 docker 结合,做集群可伸缩性调整更加容易。
哪一个更好?
没有哪一个更优于哪一个,只有最适合您自身情况的解决方案。
| 模式 | 机器数量 | 读写DFS | 维护性 | 支持Docker | 安全性 | 适合场景 |
|---|---|---|---|---|---|---|
| Local | 1 | × | 不需要维护 | × | 不安全 | 学习 |
| Standalone | 10 以内 | √ | 纯手动维护 | × | 通过所有集群管理器的共享密钥进行身份验证 | 学习 |
| YARN | 无限 | √ | 半自动化维护 | × | 身份验证,服务级别授权SLA,Web控制台身份验证和数据机密性的安全性 | 大规模生产环境 |
| Mesos | 无限 | √ | 半自动化维护 | √ | 身份验证, ACL访问控制列表用于授权访问Mesos中的服务, 支持HTTPS安全协议 | 大规模生产环境 |
| Kubernetes | 无限 | √ | 半自动化维护 | √ | 隔离环境, 提供访问安全服务的凭据, 利用Kerberos认证体系, 进行HDFS和Spark的Job执行的权限控制和授权 | 大规模生产环境 |
以上表格[3]表述了 spark 各模式所适用的场景,日常学习使用,推荐 Local 模式,日常小规模分布式任务,推荐 Standalone 模式,企业级生产应用,推荐 YARN、Mesos 或 Kubernetes。
参考文献
Cluster Mode Overview - Spark 2.4.4 Documentation[EB/OL]. [2020-01-10]. https://spark.apache.org/docs/latest/cluster-overview.html. ↩︎
Spark面试题(二)[EB/OL]. 知乎专栏, [2020-01-10]. https://zhuanlan.zhihu.com/p/49185277. ↩︎ ↩︎
Hadoop大数据平台实战(05):深入Spark Cluster集群模式YARN vs Mesos vs Standalone vs K8s_徐雷frank - jishuwen(技术文)[EB/OL]. [2020-01-10]. https://www.jishuwen.com/d/2ZHU. ↩︎




