这里使用一部 90 多万字小说《琉璃美人煞》为例,使用 LSTM 方法做一次文本生成。
从一句预测下一句
Input data: '玑庸懒外表下的,是一颗琉璃般清澈冰冷的心,前世种种因果,让她今世不懂情感。对修仙'
Target data: '庸懒外表下的,是一颗琉璃般清澈冰冷的心,前世种种因果,让她今世不懂情感。对修仙的'
Input data: '人来说,有心者,凡间即天庭。那么,有心者,是不是可以琉璃亦血肉?天下闻名的簪花大'
Target data: '来说,有心者,凡间即天庭。那么,有心者,是不是可以琉璃亦血肉?天下闻名的簪花大会'
Input data: '前夕,璇玑被选为摘花人,与父亲和师兄钟敏言下山狩猎妖魔,并结识了离泽官弟子禹司凤'
Target data: '夕,璇玑被选为摘花人,与父亲和师兄钟敏言下山狩猎妖魔,并结识了离泽官弟子禹司凤。'
|
Input data 是 X,Target data 是 Y。
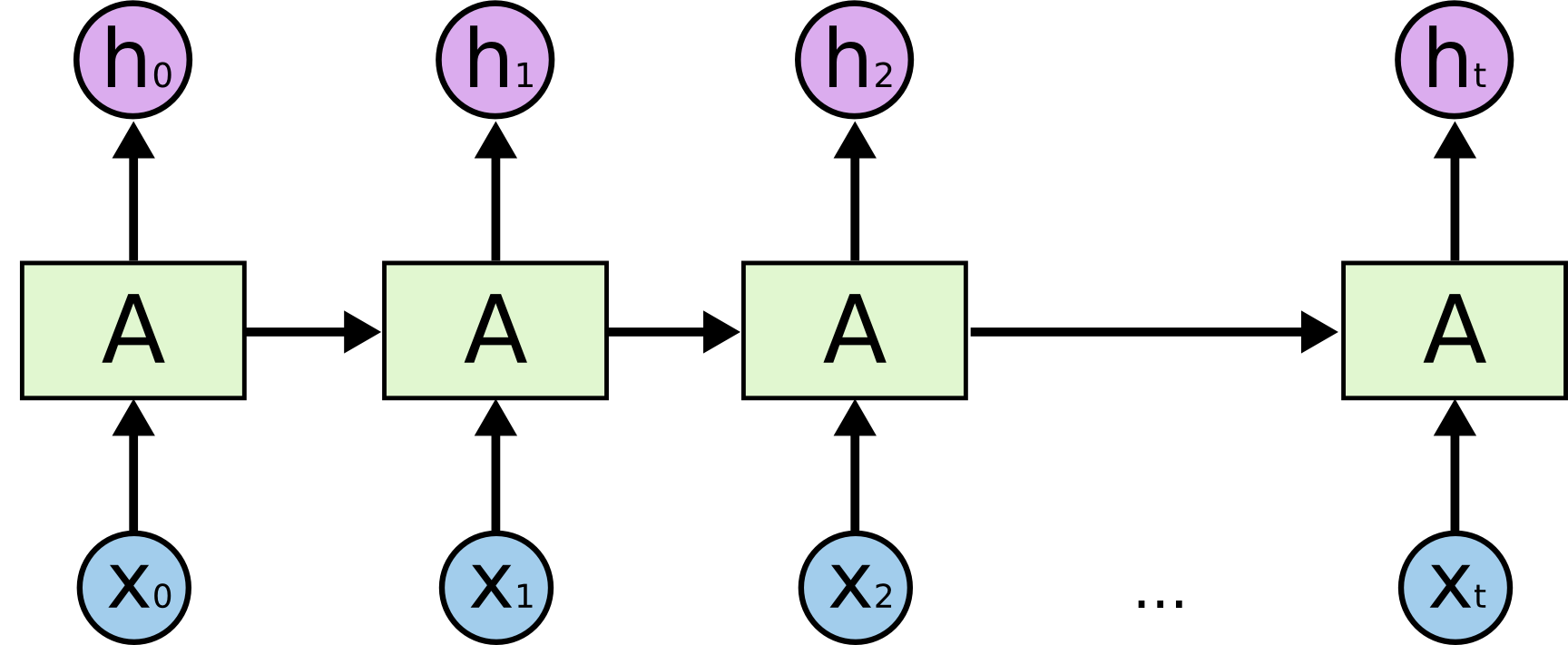
在 LSTM 的参数中,设定 return_sequences=True 让每个状态向量都参与到对下一个字的预测任务中来。
在下图中的每一个 h 向量上面都接上一个 Dense Layer,做输出,所以就可以预测出和输入序列长度相同的目标序列。

从一句预测下一字
Input data: '玑庸懒外表下的,是一颗琉璃般清澈冰冷的心,前世种种因果,让她今世不懂情感。对修仙'
Target data: '的'
Input data: '人来说,有心者,凡间即天庭。那么,有心者,是不是可以琉璃亦血肉?天下闻名的簪花大'
Target data: '会'
Input data: '前夕,璇玑被选为摘花人,与父亲和师兄钟敏言下山狩猎妖魔,并结识了离泽官弟子禹司凤'
Target data: '。'
|
Input data 是 X,Target data 是 Y。
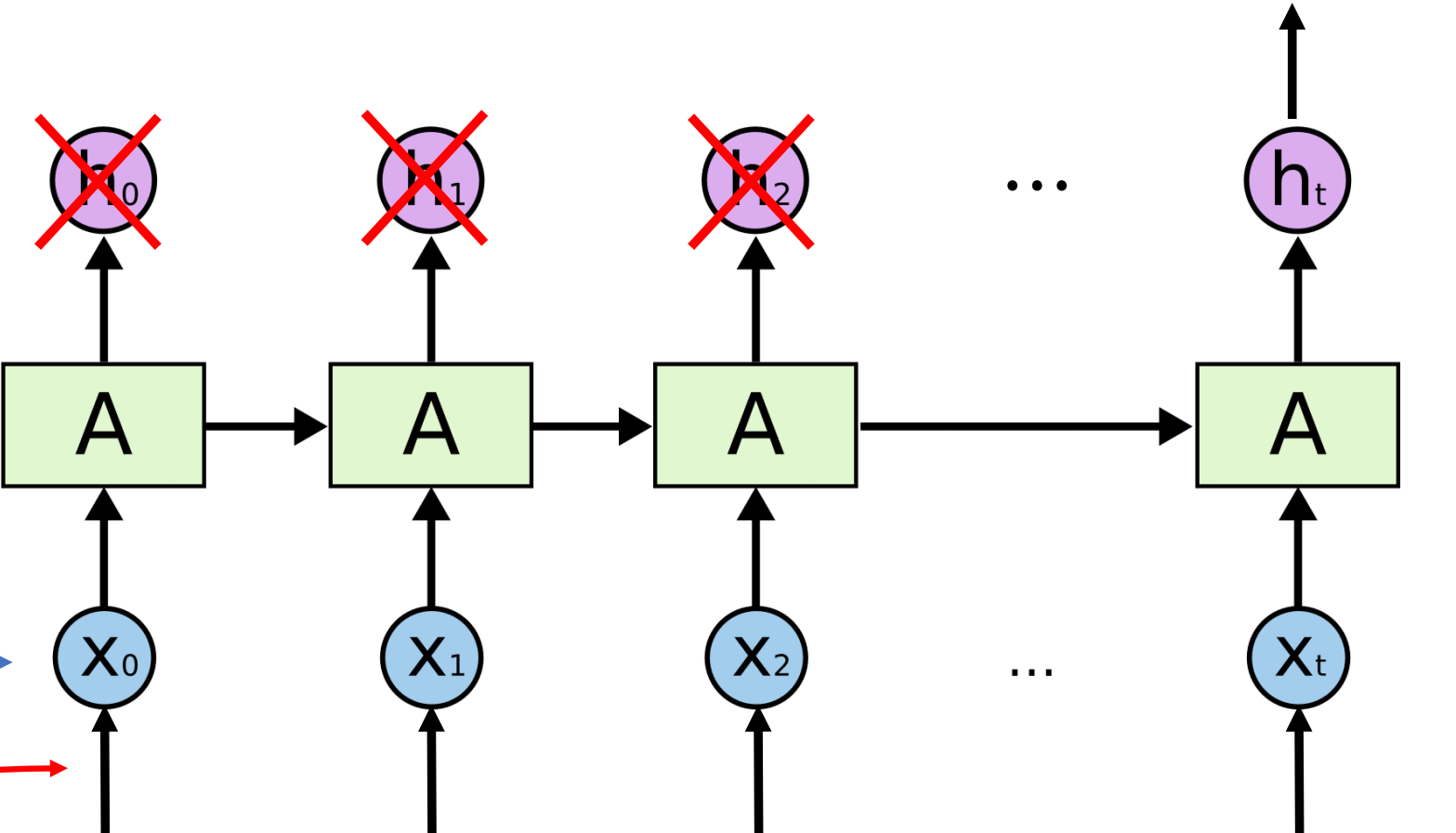
在 LSTM 的参数中,设定 return_sequences=False 只让最后一个状态量 ht 参与到对下一个字的预测任务中来。
在下图中的 ht 向量上面都接上一个 Dense Layer,做输出,所以就可以预测出长度为 1 的目标序列。