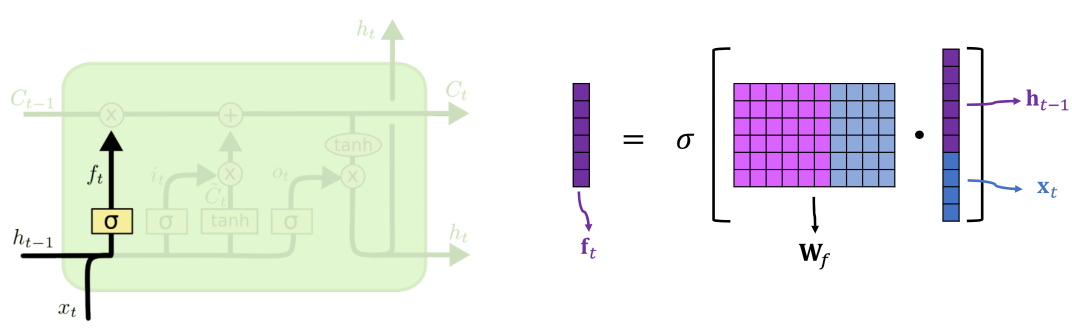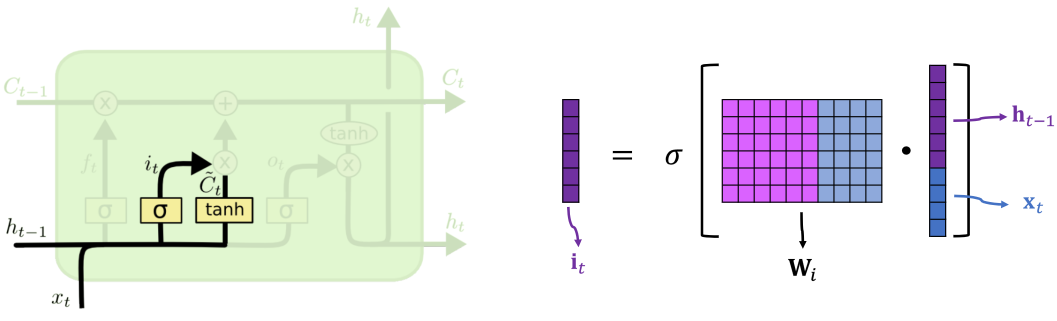LSTM 是在 1997 年被提出来的。
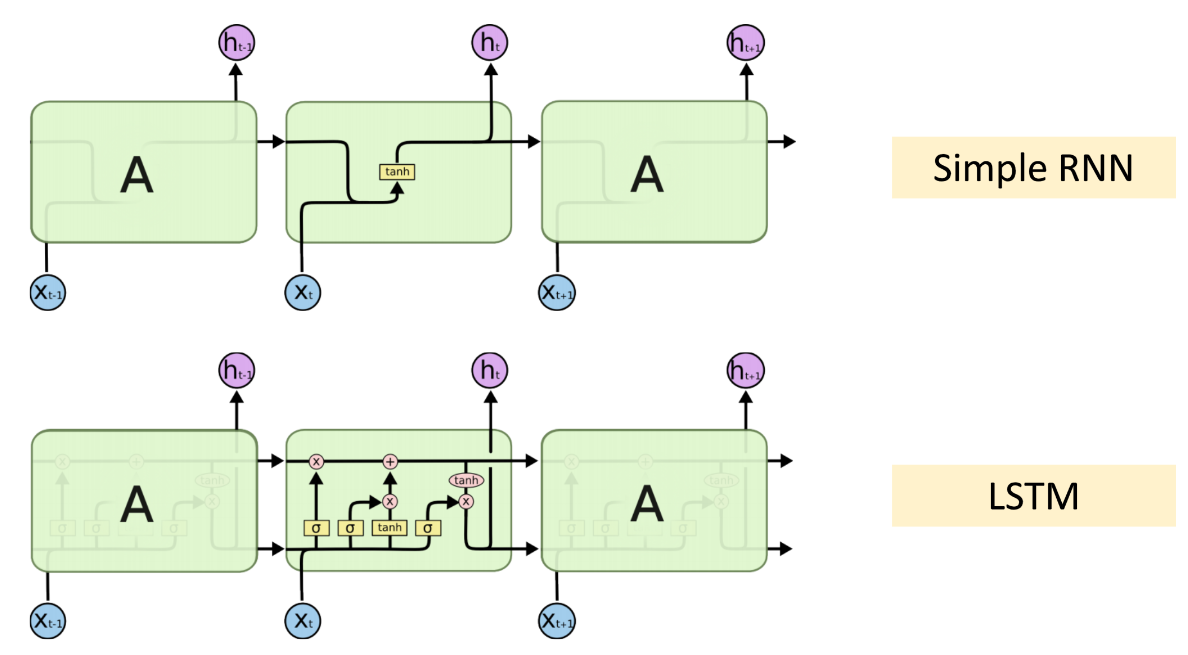
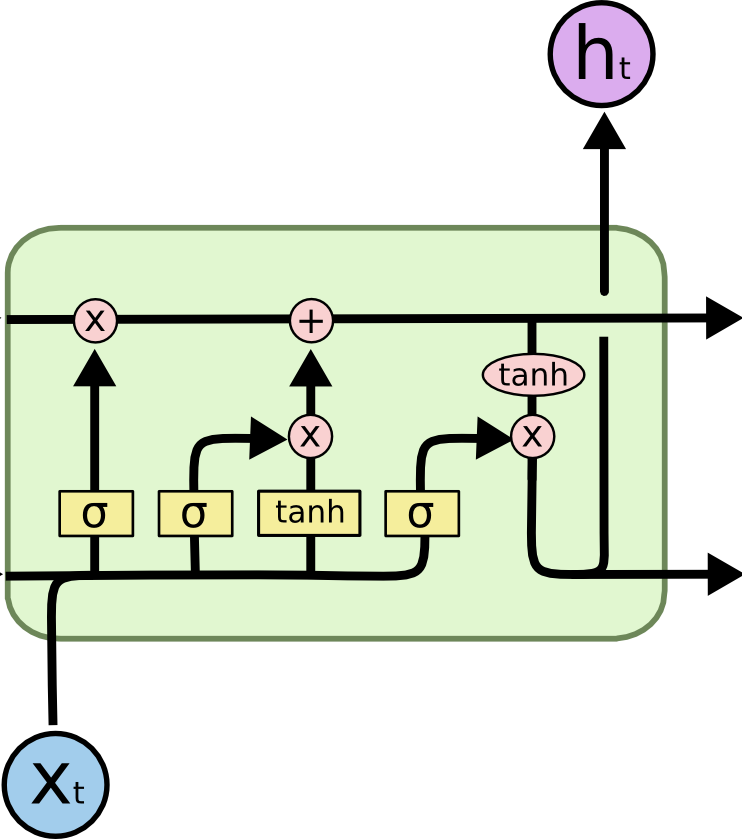
LSTM 结构

LSTM 的结构比 RNN 要复杂,其中包含 4 个参数矩阵(相比于 RNN 只有一个参数矩阵),可从训练数据中反向传播而得到更新学习。
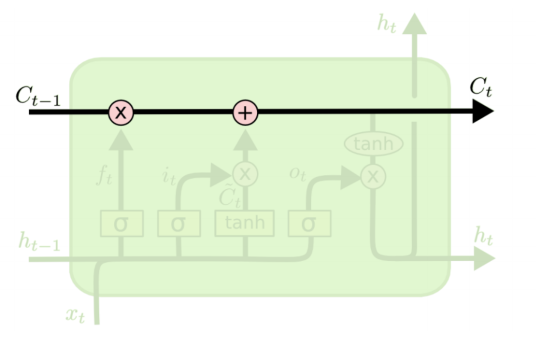
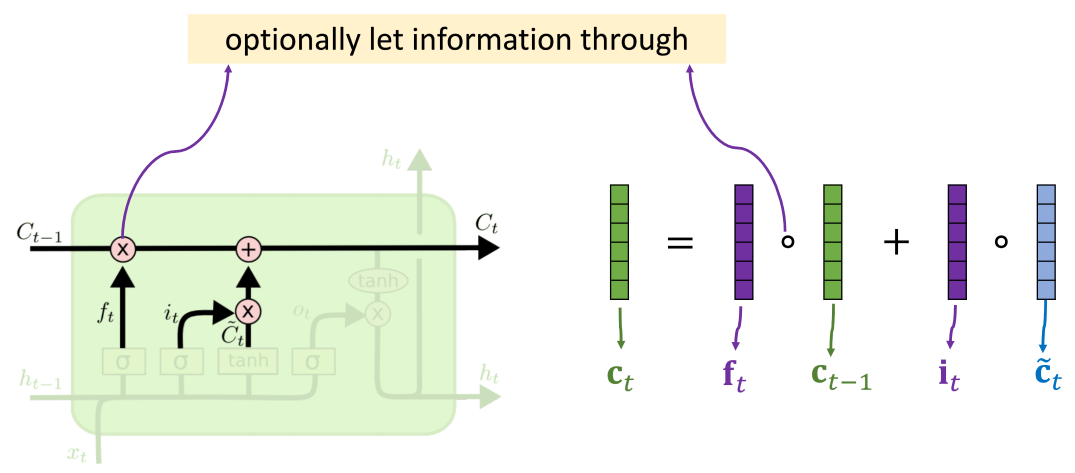
传送带
LSTM 中有一个传送带,可以将过去的信息 Ct−1 直接传递给未来的 Ct
四个参数矩阵
遗忘门
遗忘门(forget gate)Wf 决定什么数据能通过,什么不能通过,或者通过百分之多少,σ 是 Sigmoid function
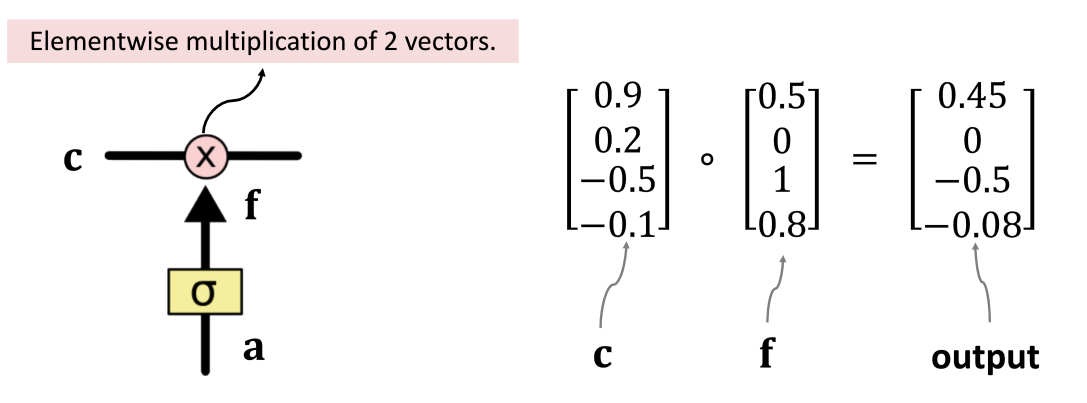
遗忘门计算出来的 ft 和 c 向量逐元素相乘,得到结果,在传送带上面继续往下走。
输入门
输入门(input gate)Wi 决定传送带上要更新的值
ht−1 和 xt 拼接在一起,点乘参数矩阵 Wi ,其结果通过 sigmoid 函数得到输入门结果 it
新值
新值(new value)c~t 代表要加入传送带上的新值
ht−1 和 xt 拼接在一起,点乘参数矩阵 Wc ,其结果通过 tanh 函数得到输入门结果 c~t。
然后 **遗忘门的结果 **和
(输入门和新值逐元素相乘的结果)相加得到新的结果作为 ct,送到传送带上。
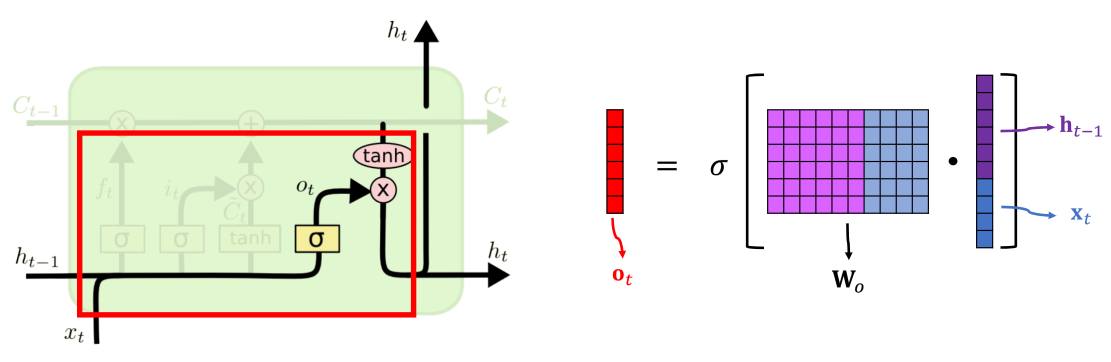
输出门
输出门(output gate)Wo 决定如何从 ct−1 得到 ht
ht−1 和 xt 拼接在一起,点乘参数矩阵 Wo ,其结果通过 sigmoid 函数得到输入门结果 ot。
ot 和刚刚计算出来放在传送带上的 ct (经过双曲正切函数激活)逐元素相乘得到最终的 ht。
ht 分两份,一份作为本单元(unit)的输出,一份传递到下一个 LSTM 单元(unit)。
LSTM 参数
4 个参数矩阵,每个的大小都和一个 SimpleRNN 一样。所以参数数量是 RNN 的 4 倍。
LSTM 实践
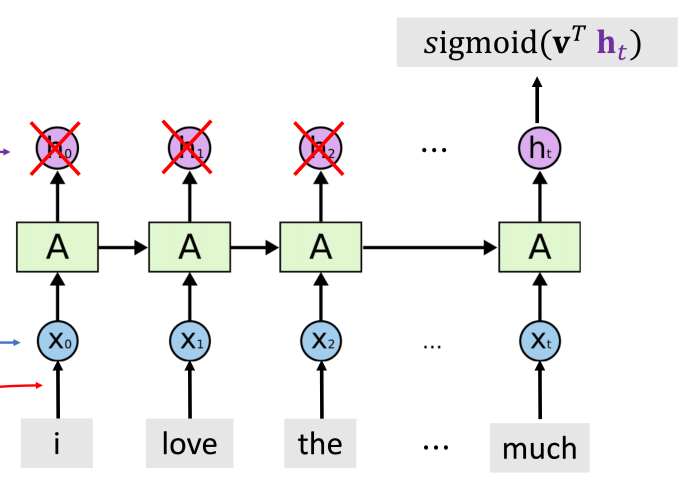
在使用的时候,通过指定 return_sequences=False 可以只用最后一个状态 ht,设置 stateful=True可以使下一个 batch 训练时使用上一个 batch 训练的 ht 结果作为此次 batch 的输出 h0。
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_size, input_length=seq_length),
tf.keras.layers.LSTM(state_dim, return_sequences=False, stateful=True),
tf.keras.layers.Dense(1, activation="sigmoid")
], name="LSTM")
model.summary()
|
Model: "LSTM"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 25, 512) 5120000
_________________________________________________________________
lstm (LSTM) (None, 1024) 6295552
_________________________________________________________________
dense (Dense) (None, 1) 1025
=================================================================
Total params: 11,416,577
Trainable params: 11,416,577
Non-trainable params: 0
_________________________________________________________________
|
当然,LSTM 也可以做成双向的(Bi-directional LSTM),因为 LSTM 也会有遗忘问题,也可以把 LSTM 叠起来(Stacked LSTM)使用,增加参数矩阵的数量。