为什么要 RNN
全连接的逻辑回归有什么局限性?
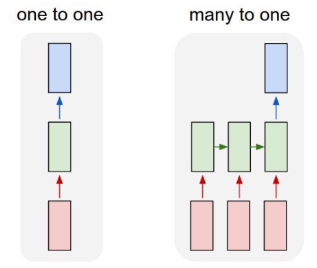
- 将整段文字一起处理(one to one)
- 输入输出是固定的形状
RNN(Recurrent Neural Networks 循环神经网络)更适合序列数据(many to one)。

RNN 内部详解
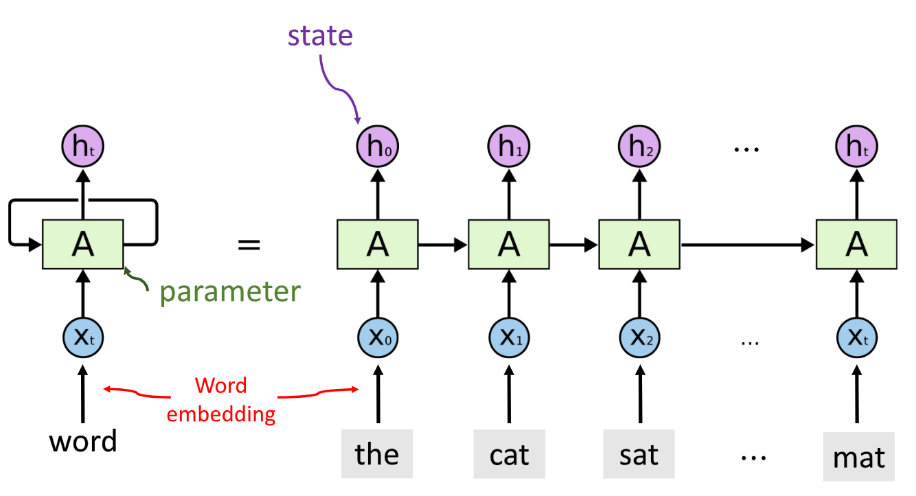
循环神经网络,顾名思义,单词一个一个的进行训练,x0 和初始 0 向量拼接在一起,与 A 矩阵,计算出 h0,再将 h0 和 x1 拼接在一起,与同一个 A 矩阵,计算出 h1,以此类推,直到句子中的每一个词都计算完毕,得到 ht 向量作为 RNN 的输出。 ht 中包含所有输入词的特征。
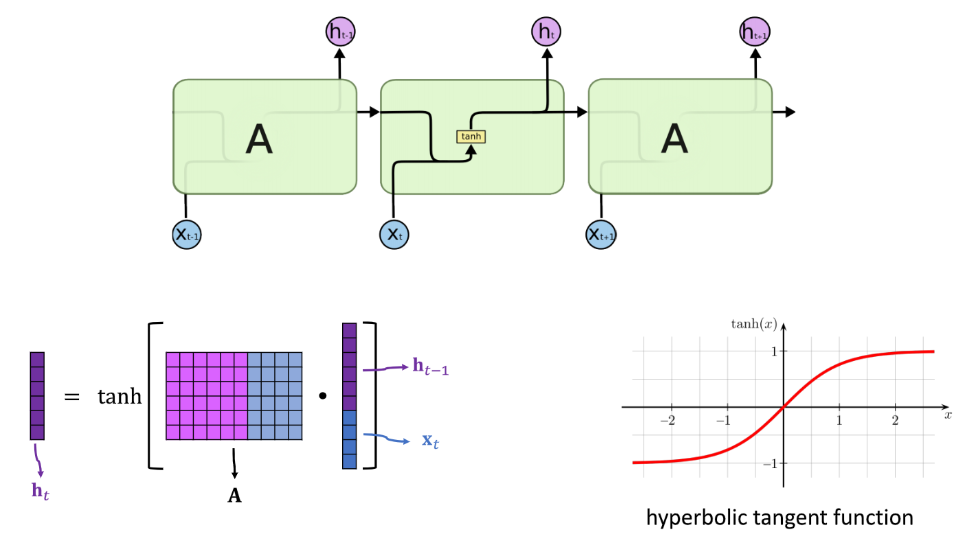
在每一步计算的过程中,使用的是 xt 和 ht−1 拼接后与 A 矩阵点乘,得到的结果通过双曲正切函数,正则化到 -1 到 1 之间,就得到了 ht.
- rows of A: shape(h)
- cols of A: shape(h) + shape(x)
- Total parameter: shape(h) × [shape(h) + shape(x)]
在 Keras 中调用
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_size, input_length=seq_length),
tf.keras.layers.SimpleRNN(state_dim, return_sequences=False),
tf.keras.layers.Dense(1, activation="sigmoid")
], name="SimpleRNN")
model.summary()
|
Model: "SimpleRNN"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 500, 32) 5120000
_________________________________________________________________
simple_rnn (SimpleRNN) (None, 32) 1573888
_________________________________________________________________
dense (Dense) (None, 1) 1025
=================================================================
Total params: 322,113
Trainable params: 322,113
Non-trainable params: 0
|
Embedding + SimpleRNN + Dense 就是一个简单的擅长处理序列任务的二元分类器。
RNN 参数:
p=state_dim×(state_dim+embedding_size)+state_dim=1024×(1024+512)+1024=1573,888
RNN 的特点
RNN 擅长短期记忆
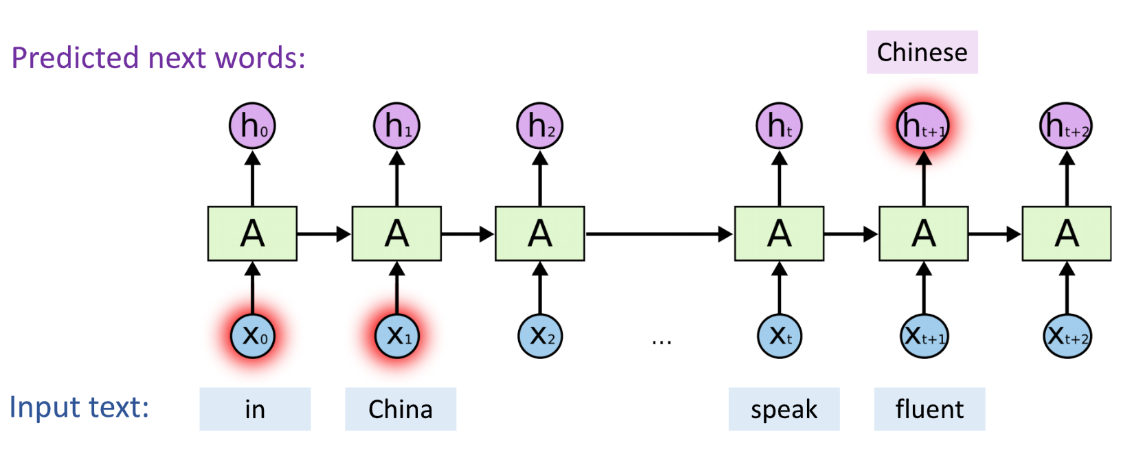
但是不擅长长期记忆:
h100 几乎与 X1 无关,∂X1∂h100 几乎等于 0,RNN 不能通过上文的 China 成功预测出 Chinese。
总结
- RNN 适合时序数据
- 状态特征 ht 聚合了所有输入的特征
- RNN 会遗忘早期的输入
- RNN的参数矩阵形状是 shape(h) × [shape(h) + shape(x)]
- RNN只有一个参数矩阵,无论序列有多长