
英文分词
“Don’t you love 🤗 Transformers? We sure do.”
-
通过空格分割:
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."] -
把标点符号单算:
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."] -
基于规则特殊处理:
如
"Don't"stands for"do not"["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
如果不基于规则特殊处理,只用空格和标点分割,会导致词表特别大,占用大量的内存和时间复杂度,比如 Transformer XL 词表高达 267735 个。如此巨大的词表,模型的嵌入矩阵(embedding matrix)也很大。
一种更节省内存和时间的方式是基于字级别的分词,英语中的字母和常用符号,不足数千,但是基于字母的方法会让模型损失性能。
所以可以将字符级别和单词级别的分词混合使用。
-
字词混合:
"I have a new GPU!"["i", "have", "a", "new", "gp", "#u", "!"]
有很多不常见的词,比如 annoyingly,而 "annoying" 和 "ly" 单独出现时更加常见,将它分开,好处是 annoyingly 的意义会被保留而且被两个更加常见的词汇替代,效果也会更好。井号代表解码时它和前面的一个字符组合在一起,构成一个新的单词
中文分词
阿迪羽绒服洗涤建议:
放3个网球里翻外翻转烘干若需要可重复翻转
古人云“句读之不知惑之不解”,这段话的真正意思是放三个网球,里翻外,翻转烘干,若需要,可重复翻转。
武汉市长江大桥
一人做事一人当,小叮当做事小叮当
中文本就有歧义,人在阅读一段文字的时候,就是通过上下文去理解、分词的过程。标点符号的出现本身就意味着中文已经到了需要分割的时候了。
中文在古代,基本上是严格的一字一意,要表达新的含义就要造新的字出来,这种表意方法在古代语义系统较为简单固定,变化不大,并且抽象程度不高的环境下是可行的,因为新字及其各组成部分基本是象形的,可以观其形而知意,并且总字数不算太多,记忆负担不大。
然而到了后来,新概念越来越多,语言变化越来越快,这种靠造新字扩展语言含义的办法就行不通了,中文逐渐发展成单字和多字词混合表意的系统特别是近现代,已经发展成以双字词为主要语义单元的系统。所以中文的分词闲的困难重重,往往分词的效果直接影响后续的任务效果。
深度学习(attention)直接把短程特征和长程特征一并处理了,并不需要再在中间划一条界线,算力也已经充足到不用刻意节约的程度。
在 WordVector 词向量相关的任务中,一般是以分词为第一步,而使用 bert 的话,更多的是以字为单位进行 tokenize,因为 bert 预训练时的语料是庞大的,可以让庞大的神经网络有充足的数据来学习每一个字之间的关系,而且是自动有监督的;WordVector 任务使用的领域内语料往往是有限的,而且是无监督的。
编码
|
vocab:
|
|
char2idx:
|
idx2char:
|
text_as_int:
|
将每个字用 One-Hot Encoding 来代表
| Word | Index | One-hot encoding |
|---|---|---|
| “movie” | 1 | e1 = [1, 0, 0, 0, 0, ⋯ , 0] |
| “good” | 2 | e2 = [0, 1, 0, 0, 0, ⋯ , 0] |
| “fun” | 3 | e3 = [0, 0, 1, 0, 0, ⋯ , 0] |
| “boring” | 4 | e4 = [0, 0, 0, 1, 0, ⋯ , 0] |
| ⋯ | ⋯ | ⋯ |
将 One-Hot Encoding 映射到低维度向量 Word Embedding
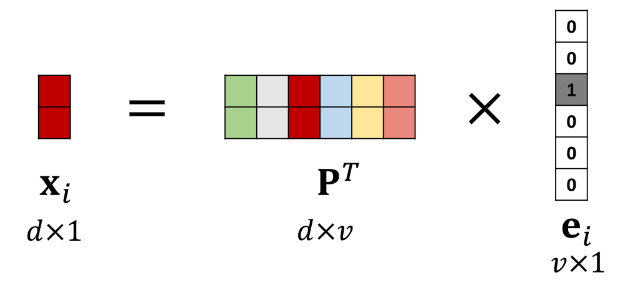
- 是可从训练数据中学习的参数矩阵
- 是字典里第 个字的 one-hot 向量
- 是目标维度, 是字典大小
|
|
构建 Logistic Regression
|
|




