
Spark join
在Spark生态里,join分为Spark SQL的join和基于dataframe的join,这次我们来谈谈最常用的基于dataframe的join方法详解示例。
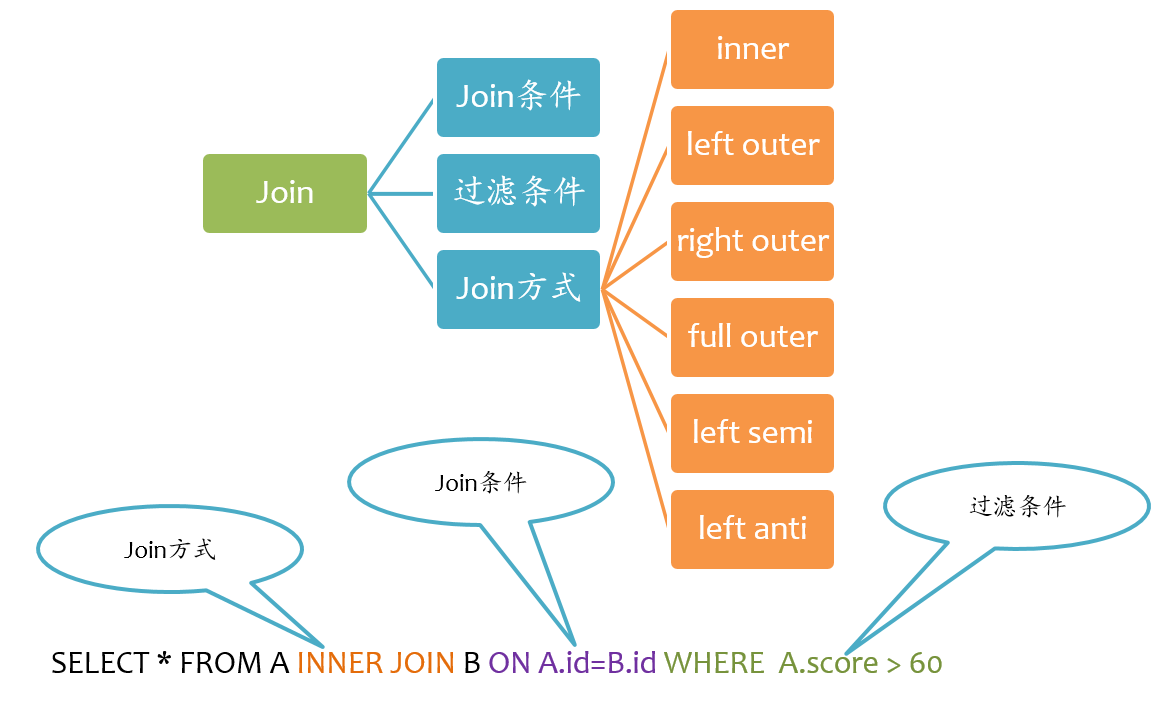
Spark支持所有类型的Join[1],包括:
- inner join
- left outer join
- right outer join
- full outer join
- left semi join
- left anti join
- cross join
下面分别阐述这几种Join的例子。
数据准备
运行环境
首先创建一下运行的类,本文将使用scalatest测试用例来做。[2]
|
基本变量
然后加载成员变量spark和sc
|
日志级别
如果觉得有需要的话,可以调高spark的默认日志级别:
|
创建数据
- 创建第一张表的数据
cid代表顾客编号(customID),name代表顾客的姓名。[2:1]
1号harbor
2号吴老师(mr.wu)
3号八宝粥(babaozhou)
|
-
第二张表
oid代表订单的ID,cid代表顾客编号(customID),amount代表此订单的金额。[2:2]
|
这两张表的数据:
- 顾客表中,顾客3:babaozhou,没有产生订单;
- 订单表中,订单5:顾客id1000,在顾客表中没有此人。
示例
inner join
inner join 是我们一般比较熟悉也经常用的一种方式。
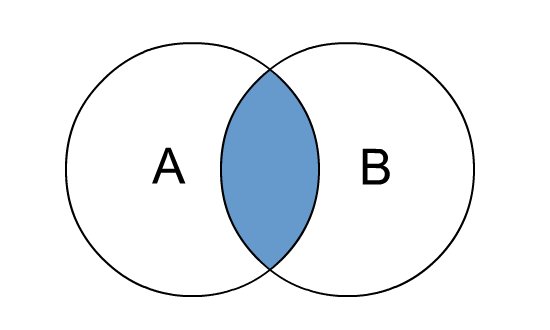
inner join 相当于是要把两个集合中重叠的部分作为结果,要求是此id在左侧出现了,同时也在右侧出现了。
|
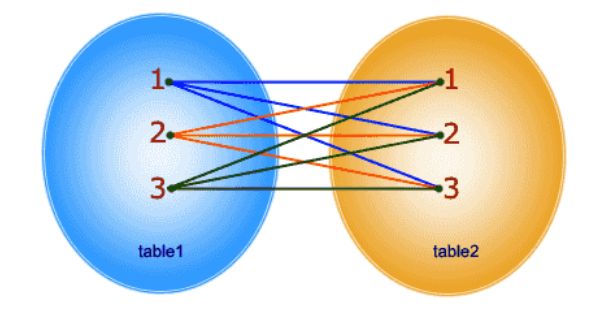
cross join
cross join 会生成笛卡尔积,也就是说,左边的每一项和右边的每一项都一一连接,简单来说就是:我们的顾客表有3个人,订单表有5个订单,那么应用 cross join 最终就会有15条数据。
|
outer join
在spark里面,outer, full, fullouter, full_outer都代表的是outer join。
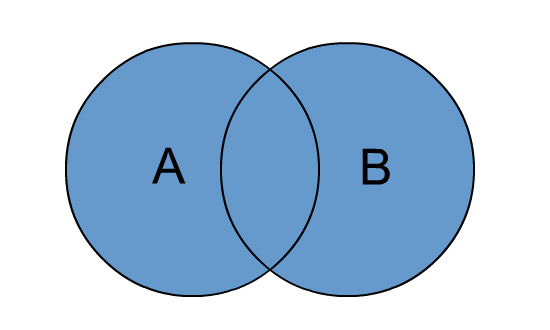
outer join 就是两个集合的全集,包括两个集合key对不上的null数据。简单来说就是:相比内连接多了null数据。
|
left join
在spark里面,left, leftouter, left_outer都代表的是left join。
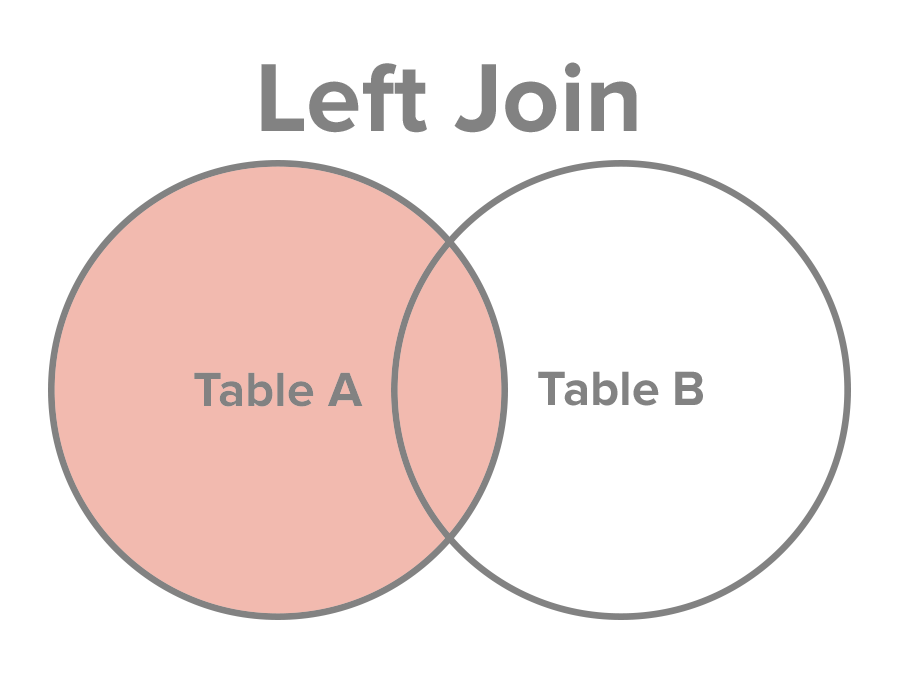
left outer join 相比内连接多了左边key不为null的null数据。
下面代码是 customer join order 的例子:
有一个在订单表中找不到对应订单的人也出现了。
|
下面代码是 order join customer 的例子:
有一个在顾客表中找不到对应人的订单也出现了。
|
right join
rightouter, right, right_outer都指的是同一种join方式。和left join 很像,right join 只是顺序颠倒过来,很好理解。
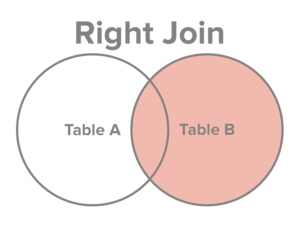
下面代码是 customer join order 的例子:
有一个在顾客表中找不到对应人的订单也出现了。
|
下面代码是 order join customer 的例子:
有一个在订单表中找不到对应订单的人也出现了。
|
lefi semi join
左半连接,又可以叫leftsemi, left_semi。正如其名字暗示的一样,他只会按照条件和顺序去 join ,然后凭 join 结果只去左边表的列,并不会把两张表合并到一起,相当于右边的表只是作为判定使用,并不会掺和进结果中。
下面代码是 order join customer 的例子:
最终结果不会出现两边的空数据,顾客ID为1000的那个订单5就不会出现在最终的结果里。
|
下面代码是 customer join order 的例子:
最终结果不会出现两边的空数据,八宝粥(babaozhou)同学没有产生过订单,那么就不会出现在最终的结果里。
|
left anti join
leftanti和left_anti是同样的意思,相当于两个集合相减。
下面代码是 customer join order 的例子:
最终结果只出现两边的空数据,八宝粥(babaozhou)同学没有产生过订单,那么就会出现在最终的结果里。也就是说:
|
最终的结果只剩下八宝粥(babaozhou)同学。
|
下面代码是 orders join customers 的例子:
最终结果只出现两边的空数据,顾客ID为1000的那个订单5就会出现在最终的结果里。也就是说:
|
最终的结果只剩下顾客ID为1000的那个订单5。
|
总结
Spark里面join方法,种类丰富,能满足日常遇到的几乎一切问题。
但是由于其是shuffle操作,是巨大的计算开销,所以在使用的时候也需要关注性能优化,比如:
- 设置参数
spark.sql.autoBroadcastJoinThreshold的值(默认10M)[1:1],让小表被广播到每个节点,以降低大表的 I/O 开销,提升性能。 spark默认sort merge join,可以看情况创造条件使用hash join提升性能。
完整的代码可以再这里找到:https://gist.github.com/c0f8a928dfe75aaf85cf9aab3708593a
参考文献
Spark SQL 之 Join 实现[EB/OL]. 守护之鲨, [2019-11-04]. http://sharkdtu.com/posts/spark-sql-join.html. ↩︎ ↩︎
types in Spark SQL[EB/OL]. [2019-11-04]. https://www.waitingforcode.com/apache-spark-sql/join-types-spark-sql/read. ↩︎ ↩︎ ↩︎




