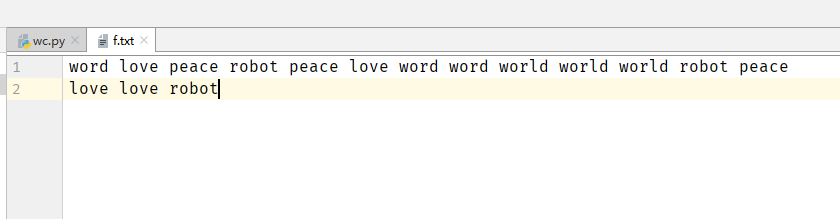
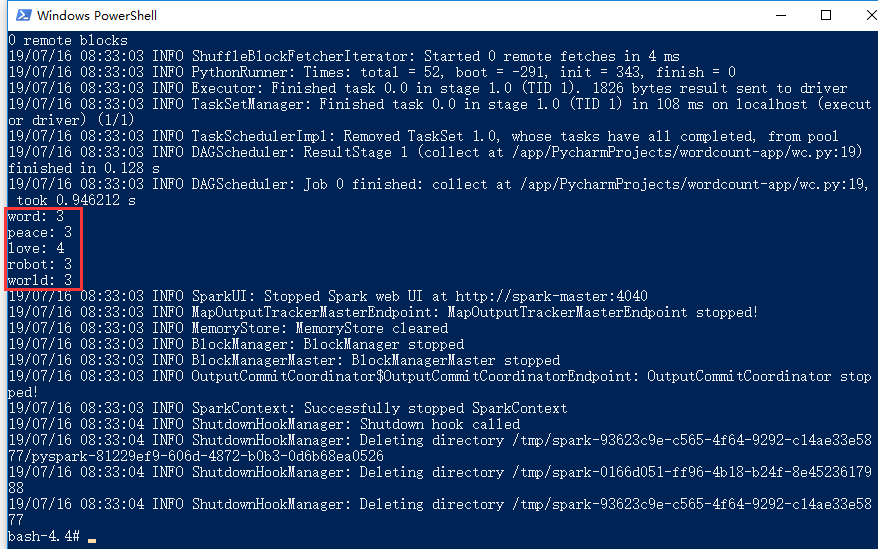
$ /spark/bin/spark-submit wc.py f.txt 19/07/16 08:32:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 19/07/16 08:32:59 INFO SparkContext: Running Spark version 2.4.1 19/07/16 08:32:59 INFO SparkContext: Submitted application: PythonWordCount 19/07/16 08:32:59 INFO SecurityManager: Changing view acls to: root 19/07/16 08:32:59 INFO SecurityManager: Changing modify acls to: root
......more output ......
word: 3 peace: 3 love: 4 robot: 3 world: 3
......more output ......
19/07/16 08:33:04 INFO ShutdownHookManager: Deleting directory /tmp/spark-93623c9e-c565-4f64-9292-c14ae33e5877/pyspark-81229ef9-606d-4872-b0b3-0d6b68ea0526 19/07/16 08:33:04 INFO ShutdownHookManager: Deleting directory /tmp/spark-0166d051-ff96-4b18-b24f-8e4523617988 19/07/16 08:33:04 INFO ShutdownHookManager: Deleting directory /tmp/spark-93623c9e-c565-4f64-9292-c14ae33e5877