
前言
docker 是一个容器化技术的程序。不仅适用于微服务集群部署,而且作为开发者个人使用,也是十分方便的,比如我们可以快速安装数据库,缓存等中间件,丝毫不影响物理机的系统环境,不会因为卸载,更新等,带来不可预知的问题,也减少了重装系统的可能性。

在容器化技术,docker 一直走在前列,docker 是用 go 语言编写的一个容器平台,他的基本单位是容器,每个容器就像一个独立的操作系统一样,可以在自己封闭的环境里独立运行,其中,容器是由镜像生成的。
所以使用 docker 的一般顺序是,拉取(或自己构建)镜像,然后由镜像生成一个或多个容器,然后启动容器,开始使用。
Hadoop 版本介绍
- Apache Hadoop
- 完全开源免费、社区活跃、文档,资料详实
- 复杂的版本管理
- 复杂的集群部署、安装、配置
- 复杂的集群运维。对集群的监控,运维
- 复杂的生态环境
- CDH: Cloudera Distributed Hadoop
- 基于Apache协议,100%开源
- 最早出现,拥有最多的部署案例
- 提供强大的部署、管理和监控工具
- 开发并贡献了可实时处理大数据的Impala项目
- HDP: Hortonworks Data Platform
- 开创性地极大地优化了Hive项目
- 开发了很多增强特性并提交至核心主干
- 100%开源,总是有最新版本的 Hadoop
- 其他

其中在第三发发行版中,国内应用较多的是Cloudera的CDH[1],我们使用 CDH 版本继续本文的内容。
准备 docker
本文使用 windows 举例,前往https://docs.docker.com/docker-for-windows/install/下载 Docker Desktop for Windows。
然后双击 exe 文件进行安装,如果遇到错误提示,请自行百度google解决。
安装 Hadoop
方式一:使用 docker pull
使用docker pull命令拉取 cloudera 官方在 docker hub 上面的快速开始仓库:
|
由于镜像文件大约 4.4 GB ,存储在 docker hub ,在线下载速度特别慢,尤其是当网络条件受限的情况下,可能需要好几天才能下载完成。所以推荐第二种下载方式:
方式二:离线导入(推荐)
docker 支持导入离线的镜像,通过使用docker import命令即可导入下载的 docker image:
|
下载
点击https://www.cloudera.com/downloads/quickstart_vms/5-13.html前往QuickStarts for CDH 5.13页面下载 docker image

然后填表,进行下载,这里的下载速度很快。
解压
下载完毕后开始解压:
|
或使用 winrar 或其他您喜欢的 GUI 解压软件进行解压。
解压完成后会在文件夹里找到名为cloudera-quickstart-vm-5.13.0-0-beta-docker.tar的文件,其大小为 6.58 GB。
导入
使用docker import命令导入 tar 文件:
|
在 tar 文件后面继续写 cloudera/quickstart:5.13.0 指明仓库名(Repository)和版本号(Tag),方便管理。
运行 Hadoop
现在已经导入了我们所下载的 hadoop 镜像,接下来就是把它在 docker 中运行起来[2]:
|
上述命令的参数解释如下:
| 参数 | 解释 |
|---|---|
| –hostname=quickstart.cloudera | 必须。伪分布式就认这个名字。 |
| –privileged=true | 必须。HBase, MySQL-backed Hive metastore, Hue, Oozie, Sentry, and Cloudera Manager 需要权限 |
| -i -t | 必须。-i 或 --interactive 可交互的,保持 STIDIN 存活;-t 或 --tty 分配一个 tty bash 来进行交互 |
| -p 8888:8888 | 推荐。把 Hue 的端口暴露到物理机。同样类似的还有 80 7180等 |
| -d | 可选。-d 或 --detach,后台运行命令 |
| /usr/bin/docker-quickstart | 必须。当容器 cloudera/quickstart:5.13.0 创建完成后,执行这个容器里面的脚本 |
脚本运行一会儿后,出现好几个 OK 的提示,就说明安装成功了。这时候我们就默认停留在了这个容器里面:
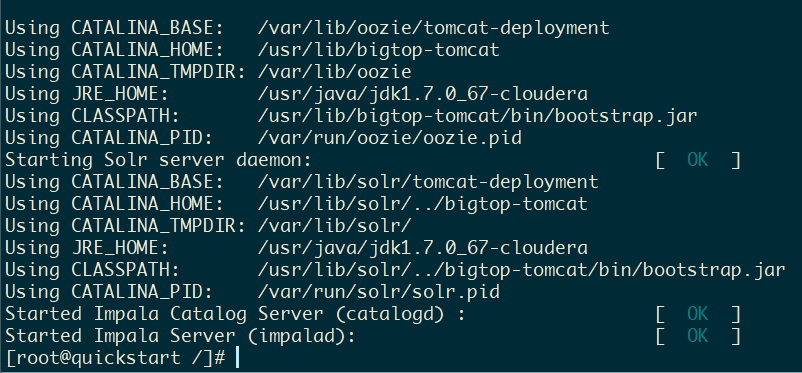
测试 Hadoop
紧接着,在终端目前所处的 [root@quickstart /]#下输入:
|
检查 java 环境:
|
进行存储文件测试:
|
cloudera live
在浏览器中输入http://localhost
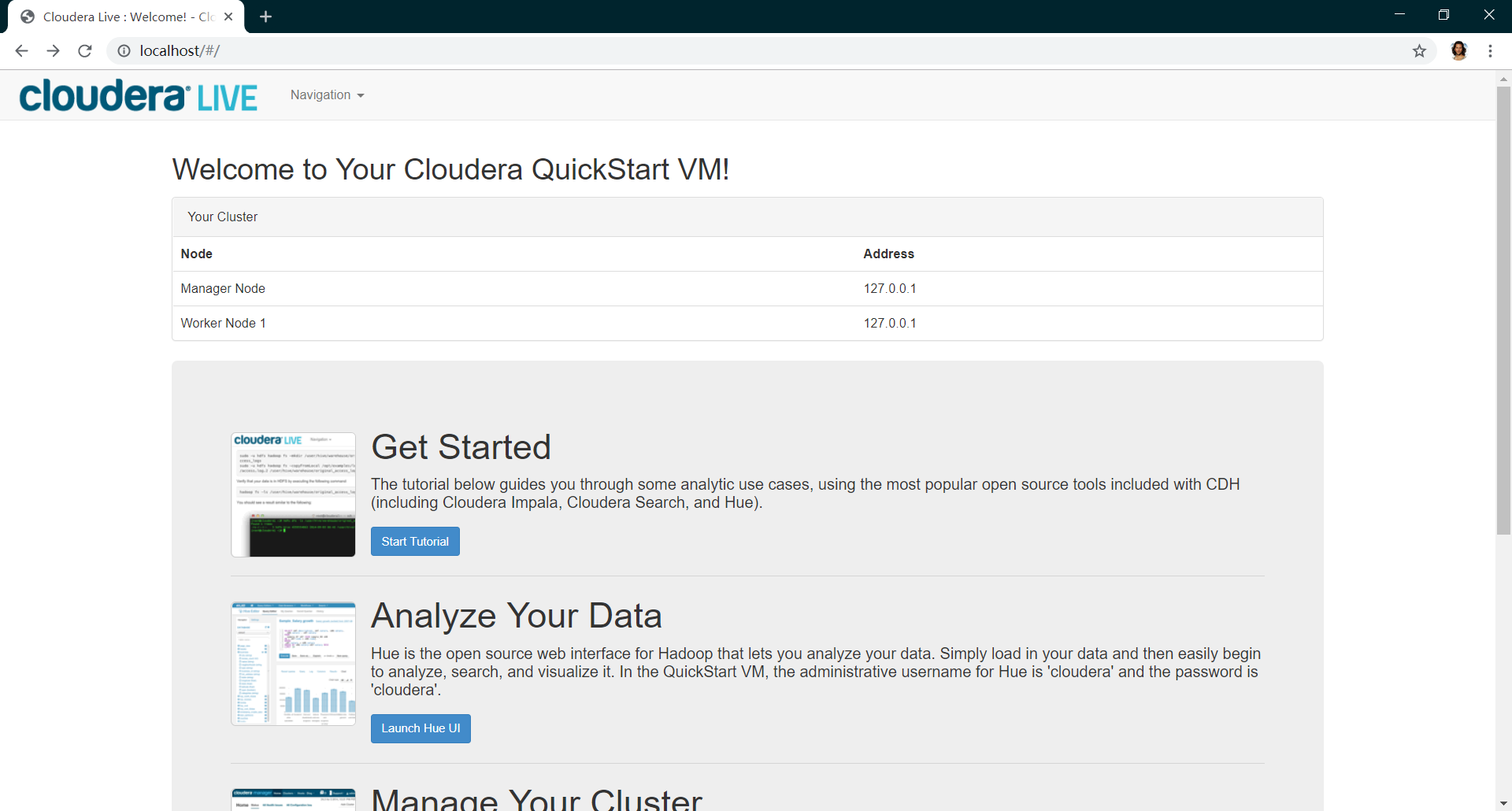
Hue
在浏览器中输入http://localhost:8888/
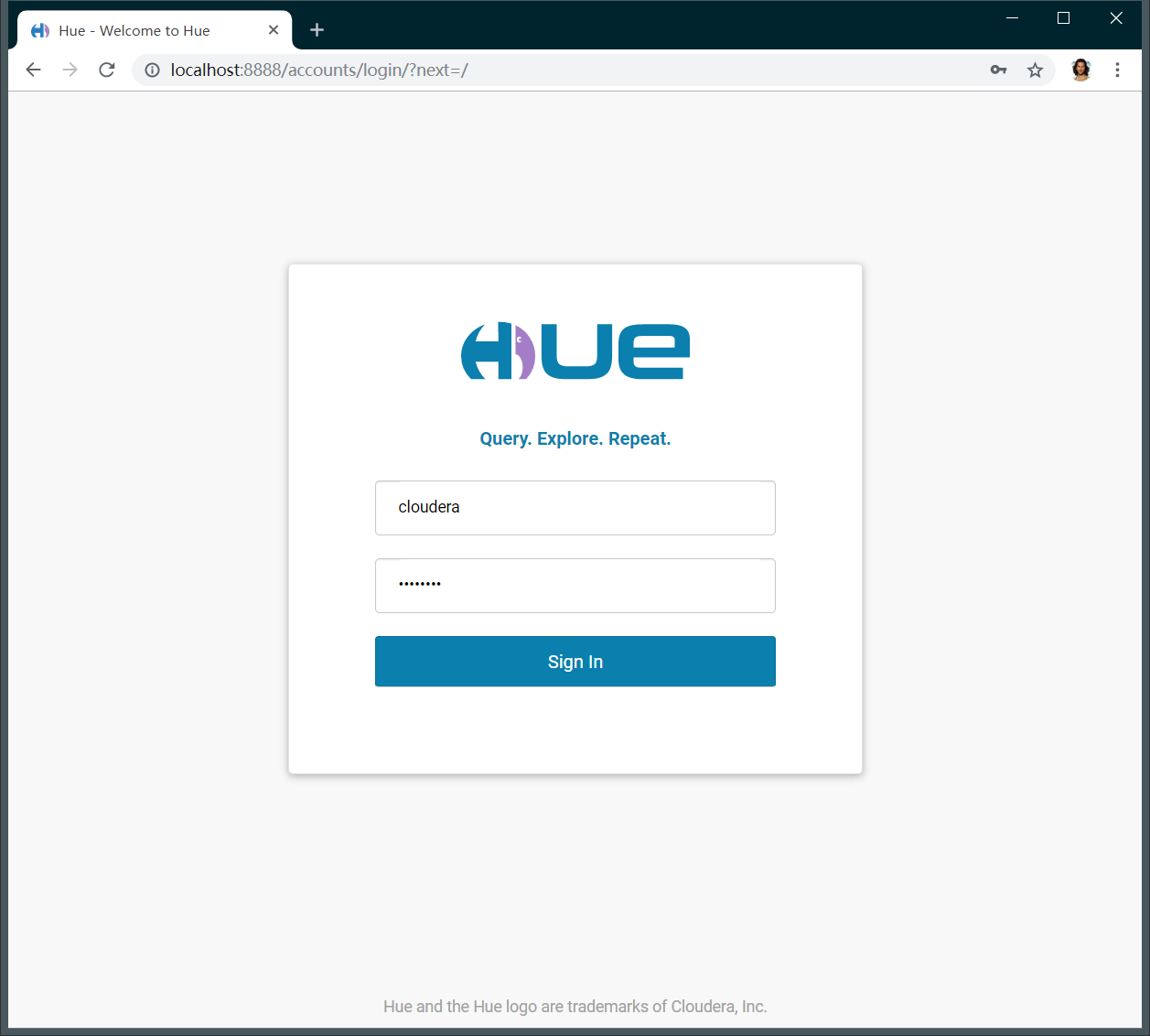
默认用户名密码为 cloudera
下次使用
关掉终端之后,如果下次想再次使用,以下命令可以帮到您:
- 查看所有的容器
|
等效于:
|
其中的STATUS如果是Exited就说明此容器已经退出了。
启动方式为:
- 启动一个容器
|
然后再执行查看所有的容器的命令,发现 cdh_study 的STATUS已经变成UP了。但是并没有出现可交互的命令行。
- 进入一个已经在运行的容器的终端命令行
如果容器的STATUS是UP使用下面命令就能重新回到容器内部的命令行:
|
或
|
这两个命令中的
container字样可以省略不写
- 查看容器输出的日志:
|
其中 -f 是持续输出。
参考资料
Apache Hadoop、CDH、HDP、MapR区别 https://blog.csdn.net/feng12345zi/article/details/83016460 ↩︎
cloudera/quickstart Single-node deployment of Cloudera’s 100% open-source Hadoop platform, and Cloudera Manager https://hub.docker.com/r/cloudera/quickstart/ ↩︎




