local 模式启动 spark 应用的过程,其实非常简单,只需简单的几步就能完成。
前言
在上一篇文章中,我们说到:
Local 模式即单机模式,也就是完全体会不到分布式的好处的一种模式。
如果在命令语句中不加任何配置,则默认是 Local 模式,在本地运行。
这也是最简单的一种模式,所有的 Spark 进程都运行在一台机器或一个虚拟机上面。
那么本章,我们一起来看看,如何搭建 Local 模式启动的 Spark 项目。
基础环境
JDK
在 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 下载适合自己电脑的 JDK,版本是 JDK 8,如果是 Spark 3.0+ 的话,也可以使用 JDK 11,感受新的 GC 特性。
安装完 JDK 后,检查下环境变量是否有 JAVA_HOME,具体的方法为,打开 Powershell 或 Cmd:
$ echo $JAVA_HOME
/home/harbor/jdk1.8.0_221
|
检查下环境变量 PATH 下是否有 java 命令,具体的方法为:
$ java -version
java version "1.8.0_221"
Java(TM) SE Runtime Environment (build 1.8.0_221-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
|
如果输出正常,那就说明是成功的,否则,就需要手动配置一下JAVA_HOME 和 PATH 这两个变量。
具体的做法为:
找到 JDK 的安装位置,
Windows
Windows JDK 默认的安装位置是 C:\Program Files\jdk1.8.0_221
知道位置之后,配置环境变量:
- 在开始面板中输入“环境变量”关键字,就能打开配置面板
- 在里面添加用户变量,键是
JAVA_HOME,值是C:\Program Files\jdk1.8.0_221
- 修改
PATH 变量,添加一条 %JAVA_HOME%\bin
- 保存即可
- 重新启动 Powershell 或 Cmd
- 重新运行上面的检查下环境变量的步骤
Linux/Unix
自己解压 JDK 所在的位置,比如用户目录下:/home/harbor/jdk1.8.0_221
- 打开终端,运行如下命令,配置当前用户的环境变量。
- 在最后一行加上,完事儿之后,按
Esc 键,输入英文的冒号,进入命令模式,输入 wq(保存且退出)。
export JAVA_HOME=/home/harbor/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$PATH
|
- 运行如下命令,在当前终端刷新环境变量,或重新启动终端。
- 重新运行上面的检查下环境变量的步骤
Python
现在 Spark 已经全面支持 Python3.x,对于 Python2.x 的支持也已经因为 Python2 EOL(End Of Life)告一段落,spark 3.0 将会移除对于 Python2.x 的支持。
所以直接在 https://www.python.org/downloads/ 下载新版本的 Python 安装即可,或者也可以使用 https://www.anaconda.com/distribution/#download-section Annoconda 来管理不同的 Python 版本或者不同的使用场景。
Scala
Spark 的大数据开发,离不开 Scala 语言的支持,可以不用特意安装 Scala 语言,因为 Spark 的依赖中已经有了 Scala,但是为了学习方便,建议还是单独安装一下。
- Spark 2.x 支持 Scala 2.11.x 版本,比如 2.11.8
- Spark 3.0 支持 Scala 2.12.x 版本。
你可以在 https://www.scala-lang.org/download/all.html 找到所有的历史版本。
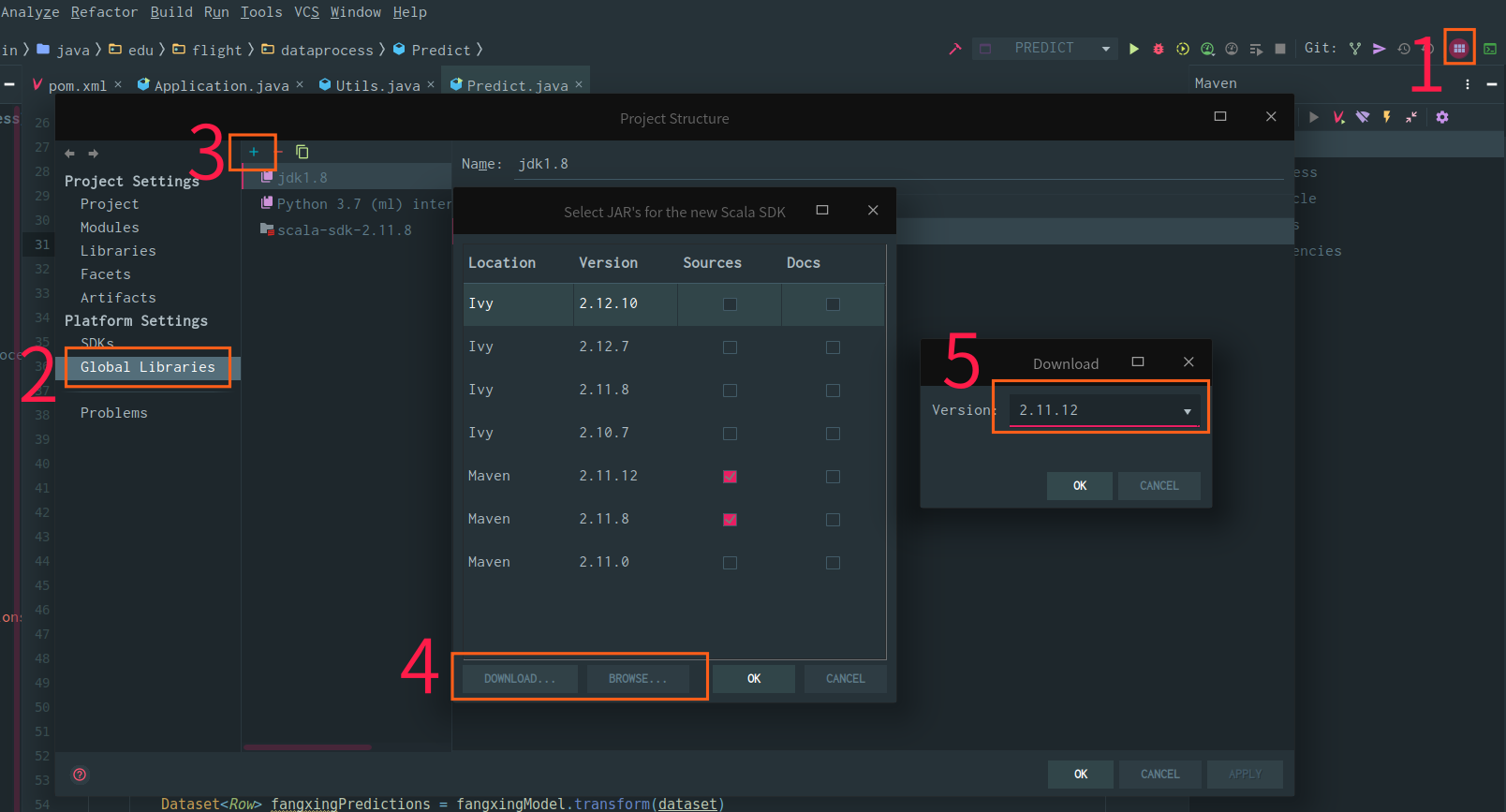
如果不想单独安装 Scala 语言开发包的话,可以使用 IDE 提供的功能,比如 Intellij IDEA 有 Scala 插件:
首先,下载安装 Intellij IDEA,或通过 JetBrains Toolbox 安装 Intellij IDEA,在初次打开的时候,导航面板中会有安装 Scala plugin 的地方,也可以通过设置-插件(Settings - Plugins - Market)查找 Scala Plugin。
然后,在新建项目的时候,就能看见 Scala 选项了,可以选择新建一个 sbt 的 scala 项目,也可以新建 Maven 项目。
在 Project Structure 配置面板中,可以找到 Global Libraries 选项卡,在此卡里面添加一项:

可以选择下载,也可以选择本地安装的 Scala。
Local 模式
winutils
要在 Windows 上运行,需要额外下载 winutils.exe ,因为 spark 版本在构建的时候,构建出来的某二进制文件只有 Linux/Unix 版本的,Windows 上运行需要重新编译或单独下载 winutils.exe。
具体方法为:
- 下载 winutils.exe http://public-repo-1.hortonworks.com/hdp-win-alpha/winutils.exe
- 创建文件夹,比如
C:\winutils\bin
- 把 winutils.exe 放到
C:\winutils\bin
- 设定环境变量
HADOOP_HOME C:\winutils
- 可能还需要注销或重启电脑才会生效
Python
以脚本方式运行
首先,通过 conda 或者 pip 命令安装 pyspark。
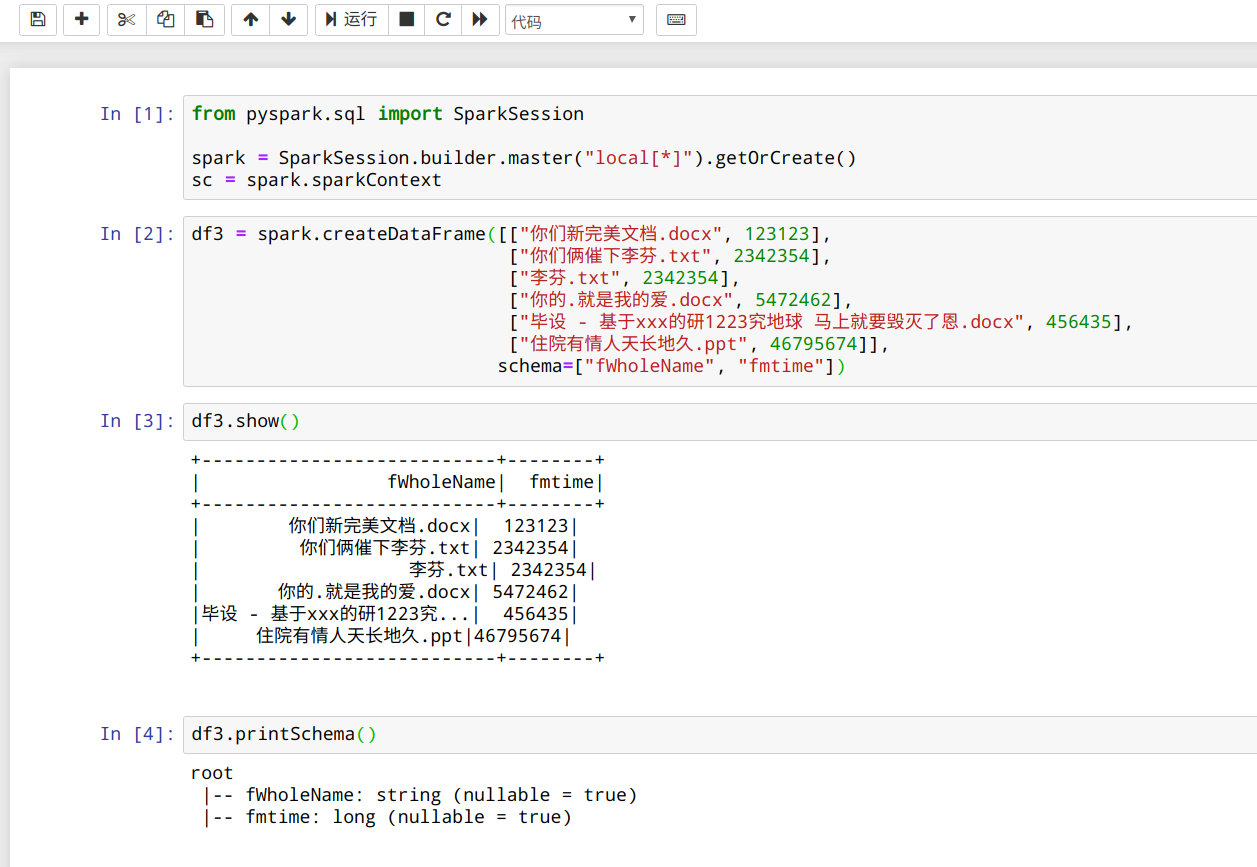
然后,创建一个 python 脚本,内容如下:
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate()
sc = spark.sparkContext
|
这样将会启动本地 spark 环境(Local 模式)。
df3 = spark.createDataFrame([["你们新完美文档.docx", 123123],
["你们俩催下李芬.txt", 2342354],
["李芬.txt", 2342354],
["你的.就是我的爱.docx", 5472462],
["毕设 - 基于xxx的研1223究地球 马上就要毁灭了恩.docx", 456435],
["住院有情人天长地久.ppt", 46795674]],
schema=["fWholeName", "fmtime"])
df3.show()
df3.printSchema()
|
右键,选择运行这些代码,控制台会有以下输出:
+---------------------------+--------+
| fWholeName| fmtime|
+---------------------------+--------+
| 你们新完美文档.docx| 123123|
| 你们俩催下李芬.txt| 2342354|
| 李芬.txt| 2342354|
| 你的.就是我的爱.docx| 5472462|
|毕设 - 基于xxx的研1223究...| 456435|
| 住院有情人天长地久.ppt|46795674|
+---------------------------+--------+
root
|-- fWholeName: string (nullable = true)
|-- fmtime: long (nullable = true)
|
在 Python Console 中运行
上述代码,在 Python Console 中也是同样支持的。
$ python
Python 3.7.4 (default, Aug 13 2019, 20:35:49)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from pyspark.sql import SparkSession
>>>
>>> spark = SparkSession.builder.master("local[*]").getOrCreate()
>>> sc = spark.sparkContext
>>> df3 = spark.createDataFrame([["你们新完美文档.docx", 123123],
... ["你们俩催下李芬.txt", 2342354],
... ["李芬.txt", 2342354],
... ["你的.就是我的爱.docx", 5472462],
... ["毕设 - 基于xxx的研1223究地球 马上就要毁灭了恩.docx", 456435],
... ["住院有情人天长地久.ppt", 46795674]],
... schema=["fWholeName", "fmtime"])
>>> df3.show()
+---------------------------+--------+
| fWholeName| fmtime|
+---------------------------+--------+
| 你们新完美文档.docx| 123123|
| 你们俩催下李芬.txt| 2342354|
| 李芬.txt| 2342354|
| 你的.就是我的爱.docx| 5472462|
|毕设 - 基于xxx的研1223究...| 456435|
| 住院有情人天长地久.ppt|46795674|
+---------------------------+--------+
>>> df3.printSchema()
root
|-- fWholeName: string (nullable = true)
|-- fmtime: long (nullable = true)
|
在 Jupyter Notebook 中运行
在终端适当目录下,启动 jupyter notebook
在打开的浏览器中新建 notebook
Scala/Java
Scala 语言基于 JVM,可以兼容 Java,所以这里归到一起举例。
由于静态语言的特性,构建和打包都需要完整的依赖,所以使用依赖管理工具,最为简单。
要新建一个 Spark 的项目,推荐的依赖管理工具是 sbt 和 Maven。
Maven
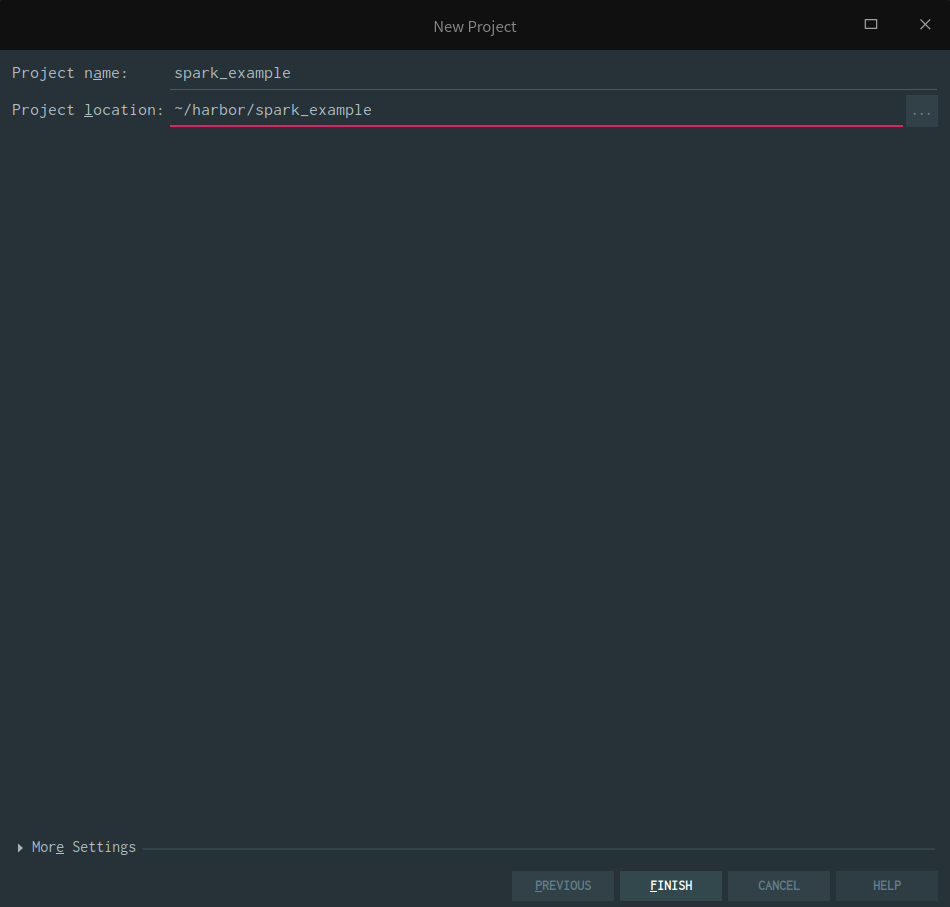
新建 Maven 项目
选择新建 Maven 项目
然后填入项目的名字
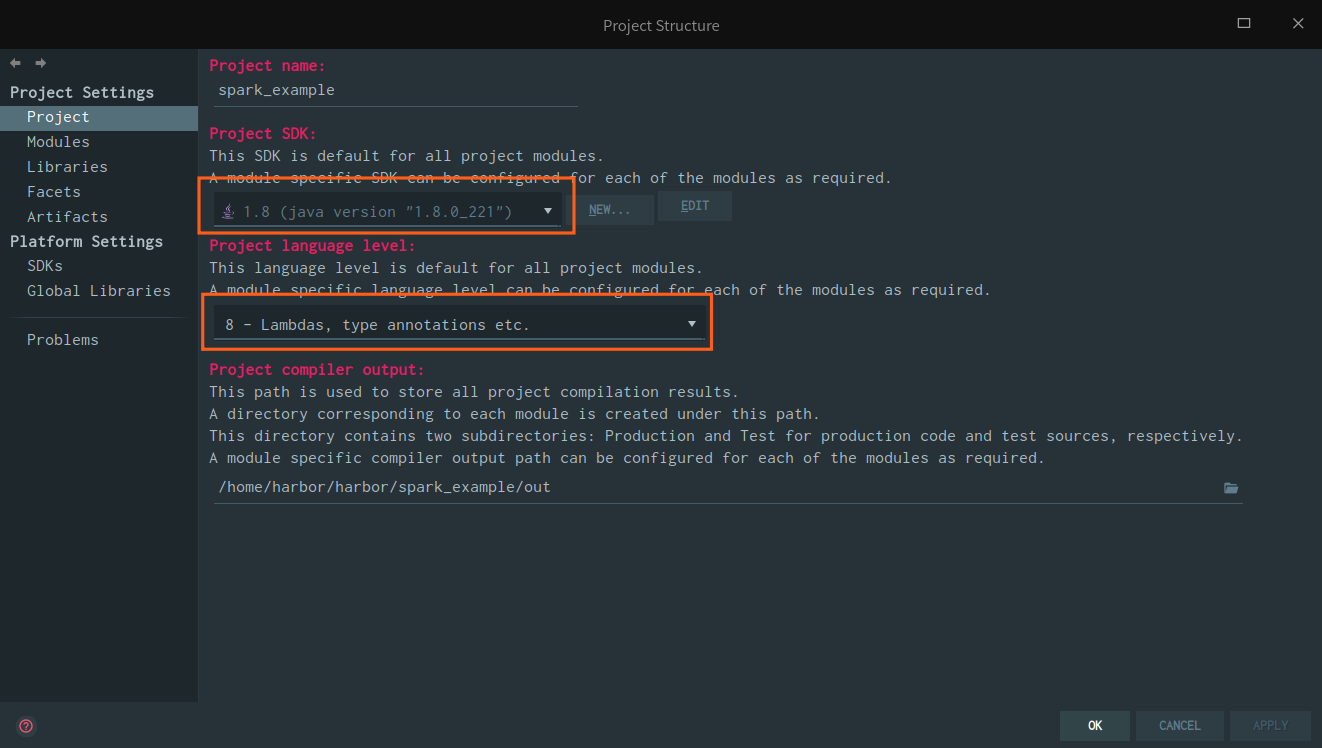
新建 Maven 项目之后,首先打开 Project Structure 面板,确定自己使用的是 JDK 8
修改 pom.xml
需要在 pom.xml 中添加必要的参数:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spark.version>2.4.4</spark.version>
</properties>
|
其次是添加 Spark 相关的依赖:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
|
然后,还要添加一些插件。
添加如下 build 标签,内包含 plugins 和 resources两个子标签:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>com.company.spark_example.Application.scala</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
<include>**/*.java</include>
</includes>
</configuration>
</execution>
<execution>
<id>scala-test-compile</id>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>2.11.8</scalaVersion>
<args>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</build>
|
其中,
maven-assembly-plugin起打包的作用,尤其是将所依赖的包也打到一起,打完的包可以单独运行maven-compiler-plugin起编译作用maven-scala-plugin起编译作用
代码
接下来就可以开始创建包名和入口文件,比如 com.company.spark_example.Application.scala
如果在 src 文件夹上右键 new 里面没有 Scala Class 选项的话,右键单击您的项目,“ 添加框架支持 ”,然后选择Scala框架。
在此之后,右键单击src> Mark directory as> Sources Root。
package com.company.spark_example
import org.apache.spark.sql.SparkSession
object Application {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").getOrCreate()
val sc = spark.sparkContext
val df3 = spark.createDataFrame(Seq(
("你们新完美文档.docx", 123123),
("你们俩催下李芬.txt", 2342354),
("李芬.txt", 2342354),
("你的.就是我的爱.docx", 5472462),
("毕设 - 基于xxx的研1223究地球 马上就要毁灭了恩.docx", 456435),
("住院有情人天长地久.ppt", 46795674)
)).toDF("fWholeName", "fmtime")
df3.show()
df3.printSchema()
}
}
|
右键运行之后,控制台会输出:
+---------------------------+--------+
| fWholeName| fmtime|
+---------------------------+--------+
| 你们新完美文档.docx| 123123|
| 你们俩催下李芬.txt| 2342354|
| 李芬.txt| 2342354|
| 你的.就是我的爱.docx| 5472462|
|毕设 - 基于xxx的研1223究...| 456435|
| 住院有情人天长地久.ppt|46795674|
+---------------------------+--------+
root
|-- fWholeName: string (nullable = true)
|-- fmtime: integer (nullable = false)
|
打包
在项目目录下,执行:
或在 IDEA 右侧面板 Maven 中展开 Lifecycle,双击 package。
在 target/ 文件夹下面,就会有类似 spark_example-1.0-SNAPSHOT-jar-with-dependencies.jar 的文件生成。
打开终端,执行:
$ java -jar spark_example-1.0-SNAPSHOT-jar-with-dependencies.jar
|
也是可以的。
总结
本篇文章主要介绍,如何以 Local 模式进行 Spark 应用的开发,由此可见, Local 模式的应用场景仅限于单机处理数据,单机的机器学习,常用于学习场景,或者本地小批量数据,跑通程序。
在程序运行过程中,进入浏览器 http://localhost:4040 还能看到 Web UI,里面有应用运行的步骤等详细信息,程序运行结束,这个页面就再也看不见了,也没有地方可以查看历史记录。
下一章,我们来讲讲如何搭建 Standalone 模式的 Spark 运行环境。