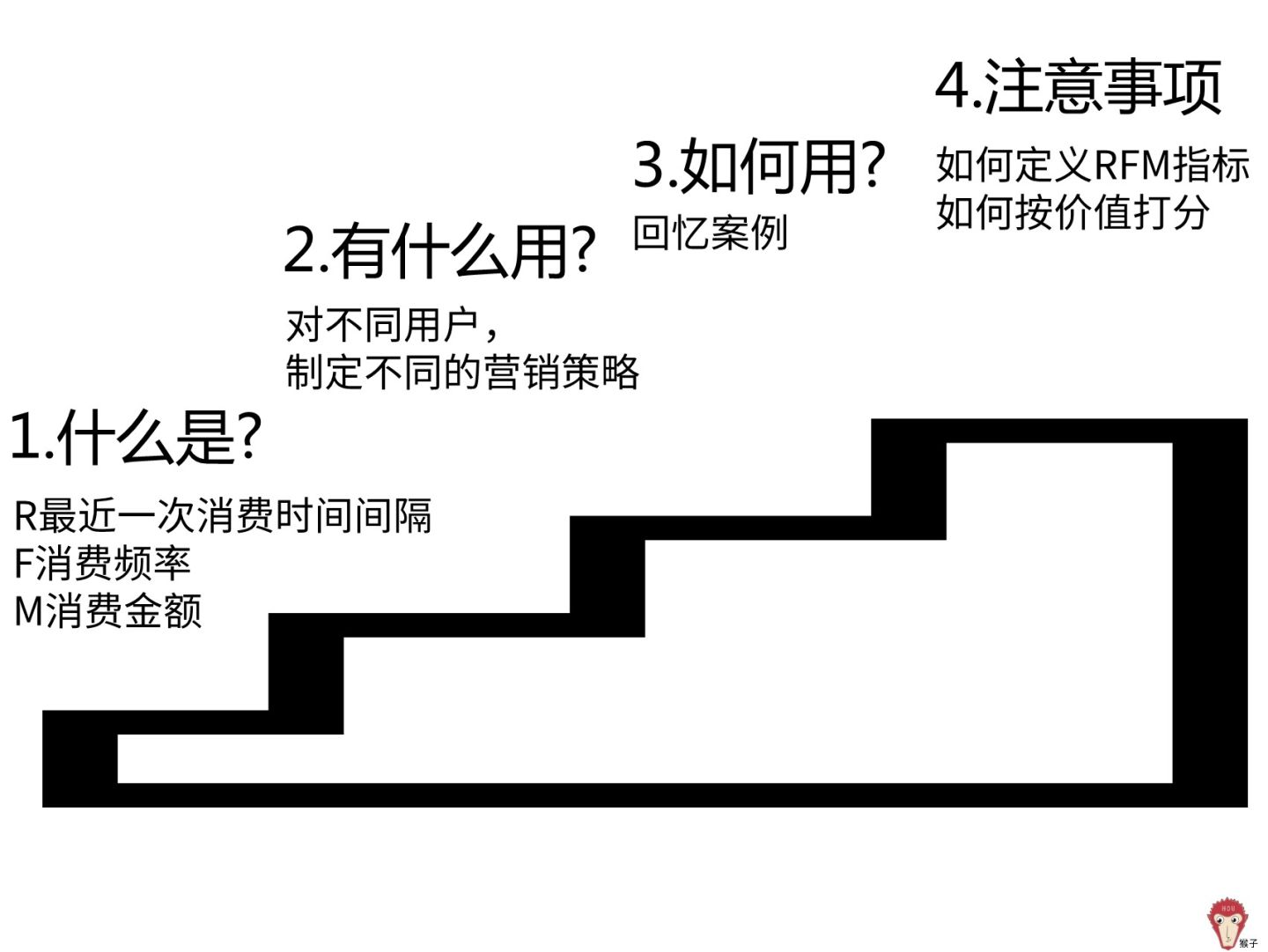
什么是 RFM 分析方法
理论
RFM是3个指标的缩写,最近一次消费时间间隔(Recency),消费频率(Frequency),消费金额(Monetary)。通过这3个指标对用户分类。
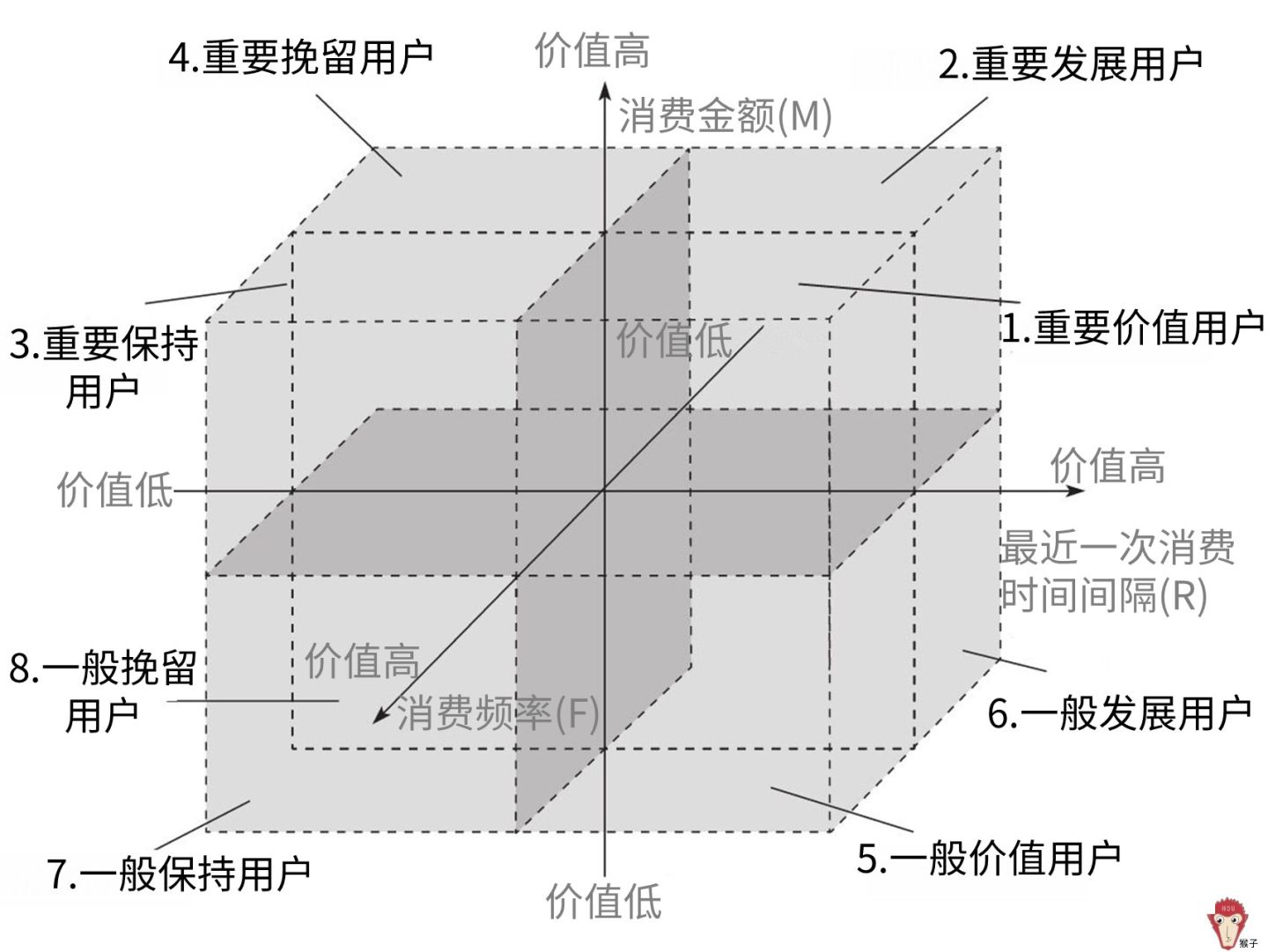
用RFM分析方法把用户分为8类,这样就可以对不同价值用户使用不同的营销决策,把公司有限的资源发挥最大的效果,这就是我们常常听到的精细化运营。比如第1类是重要价值用户,这类用户最近一次消费较近,消费频率也高,消费金额也高,要提供 vip 服务。

- 最近1次消费时间间隔(R)是指用户最近一次消费距离现在多长时间了
- 消费频率(F)是指用户一段时间内消费了多少次
- 消费金额(M)是指用户一段时间内的消费金额
更加广义上的RFM也可以是:
- 最近1次使用产品时间间隔(R)是指用户最近一次使用距离现在多长时间了
- 使用频率(F)是指用户一段时间内使用了多少次
- 使用成本(M)是指用户一段时间内的使用总时间
一段时间的定义可以根据具体的业务情况而定;使用可以指打开app等。
比如您也可以把人脉的联系使用RFM方法进行分析,他大概是这个样子:
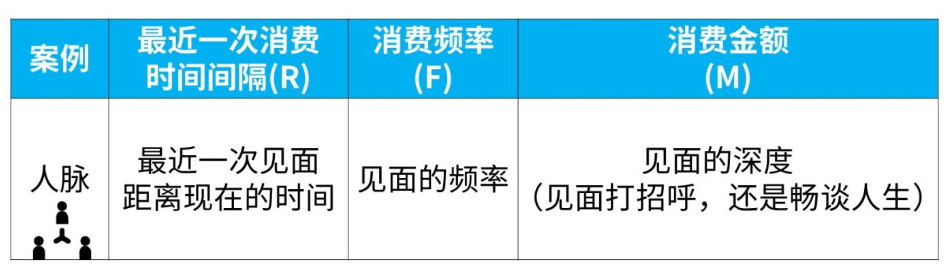
但是总体来说:
-
最近一次消费时间间隔(R),上一次消费离得越近,也就是R的值越小,用户价值越高。
-
消费频率(F),购买频率越高,也就是F的值越大,用户价值越高。
-
消费金额(M),消费金额越高,也就是M的值越大,用户价值越高。
我们把这3个指标按价值从低到高排序,并把这3个指标作为XYZ坐标轴,就可以把空间分为8部分,这样就可以把用户分为下图的8类。
实现
现有如下数据:
- uid:用户唯一标识符
- use_duration:用户某次使用产品时长
- record_time:该条信息被记录的时间
我们通过以下方式来处理:
-
读取和过滤数据
spark.read.parquet("path/to/data")
.select("uid", "use_duration", "record_time")
.filter($"uid".isNotNull and $"uid" =!= "" // 登录的用户才算有效
and $"use_duration" > 20 // 达到一定的使用时长(second)
and datediff(current_date(), $"record_time") < 90 // 过去一段时间的数据(day)
and datediff(current_date(), $"record_time") >= 0) // 过滤掉未来的数据(day) -
计算RFM
df.groupBy("uid").agg(
sum("use_duration") as "M",
count("uid") as "F",
datediff(current_date(), max("record_time")) as "R"
)
如何选取RFM阈值
聚类
由于RFM数据的量纲各不相同,数据的取值也存在很大的差异。为了消除分布差异较大和量纲不同的影响,在对各个指标进行加权之前,需要考虑对数据进行标准化处理。
一般情况中,F、M指标对顾客价值存在正相关的影响,因此其标准化调整通过 ,其中为标准化后的值,为原值,为该指标最小值,为该指标最大值。R对顾客价值存在负相关关系,因此其标准化调整公式为:
在聚类的过程中,需要预先判断其聚类的类别数。在模型中客户分类通过每个顾客类别RFM平均值与总RFM平均值相比较来决定的,而单个指标的比较只能有两种情况:大于(等于)或小于平均值,因此可能有8种类别。
实现
-
将 RFM 三值标准化(Normalize)
val minmax = rfmDF.agg(min("R"), min("F"), min("M"),
max("R"), max("F"), max("M"))
// 如果下面的代码报错不能将Long转成Int,那就需要手动改一下。
val minR = minmax.select("min(R)").head().getInt(0)
val minF = minmax.select("min(F)").head().getInt(0)
val minM = minmax.select("min(M)").head().getInt(0)
val maxR = minmax.select("max(R)").head().getInt(0)
val maxF = minmax.select("max(F)").head().getInt(0)
val maxM = minmax.select("max(M)").head().getInt(0)
val udfNormalizeR = udf((r: Int) => {
(maxR.toDouble - r.toDouble) / (maxR.toDouble - minR.toDouble)
})
val udfNormalizeF = udf((f: Int) => {
(f.toDouble - minF.toDouble) / (maxF.toDouble - minF.toDouble)
})
val udfNormalizeM = udf((m: Int) => {
(m.toDouble - minM.toDouble) / (maxM.toDouble - minM.toDouble)
})
val rfmDF = rfmWithLabelDF.withColumn("normalizedR", udfNormalizeR($"R"))
.withColumn("normalizedF", udfNormalizeF($"F"))
.withColumn("normalizedM", udfNormalizeM($"M")) -
将features聚合成vector以参与聚类训练
VectorAssembler assembler = new VectorAssembler()
.setInputCols(new String[]{"normalizedR", "normalizedF", "normalizedM"})
.setOutputCol("featuresAssembled");
rfmDF = assembler.transform(rfmDF); -
进行数据标准化(Standardize),以提升算法准确度(可选)
StandardScaler scaler = new StandardScaler()
// 一下两者选其一,一般使用默认值(Std(Scale to unit standard deviation))就好
//.setWithMean(true)
//.setWithStd(true)
.setInputCol("featuresAssembled")
.setOutputCol("features");
StandardScalerModel scalerModel = scaler.fit(rfmDF);
rfmDF = scalerModel.transform(rfmDF); -
训练
KMeans kMeans = new KMeans()
.setK(8)
.setSeed(666)
// 还有很多设置可以在这里调整,一般使用默认值就好,比如
//.setMaxIter()
//.setTol()
.setDistanceMeasure(DistanceMeasure.EUCLIDEAN());
// 训练
KMeansModel model = kMeans.fit(rfmDF);
// 保存训练之后的模型
model.write().overwrite().save("kmeans.model"); -
查看一些训练之后的信息,比如cost
KMeansSummary summary = model.summary();
logger.info("trainingCost: " + summary.trainingCost()); -
使用训练好的模型来对原始数据做一次预测并保存
// summary.predictions(); 也有同样的作用
Dataset<Row> predictions = model.transform(rfmDF);
// 把预测的数据结果保存
predictions.select("userid", "normalizedM", "normalizedF", "normalizedR", "prediction")
.write().mode(SaveMode.Overwrite).option("header", true)
.csv("path/to/save");
统计
通过分位数,观察用户成分的分布情况,提出RFM三个指标分别的阈值。
实现
-
计算相关性系数
private def calcCorr(rfm: Dataset[Row]): Unit = {
val rfCorr = rfm.stat.corr("R", "F")
logger.info(s"R F Corr is $rfCorr")
val rmCorr = rfm.stat.corr("R", "M")
logger.info(s"R M Corr is $rmCorr")
val mfCorr = rfm.stat.corr("M", "F")
logger.info(s"M F Corr is $mfCorr")
}20/03/07 01:38:00 INFO Application$: R F Corr is -0.36390210862365274
20/03/07 01:38:07 INFO Application$: R M Corr is 0.015190953608016712
20/03/07 01:38:09 INFO Application$: M F Corr is 0.01806946112236617 -
计算分位数
private def calcQuantiles(rfm: Dataset[Row]): Unit = {
val cols = Array("R", "F", "M")
val quantiles = Array(0.25, 0.5, 0.6, 0.75, 0.9, 0.95, 0.99)
val colMedians = rfm.stat.approxQuantile(cols, quantiles, 0.0d)
for ((medians, index) <- colMedians.zipWithIndex) {
logger.info(s"列: ${cols(index)}")
for ((median, index) <- medians.zipWithIndex) {
logger.info(s"median of ${quantiles(index)}: $median")
}
}
}
通过以上两步骤,可以在日志里看出数据的分布趋势,好确定RFM各自的阈值,比如设定如下阈值:
val rThreshold = 36
val fThreshold = 25
val mThreshold = 4626
-
计算用户评级
rfmDF.withColumn("label",
when($"R" < rThreshold and $"F" >= fThreshold and $"M" >= mThreshold, lit("重要保持"))
.when($"R" >= rThreshold and $"F" >= fThreshold and $"M" >= mThreshold, lit("重要价值"))
.when($"R" < rThreshold and $"F" < fThreshold and $"M" >= mThreshold, lit("重要挽留"))
.when($"R" >= rThreshold and $"F" < fThreshold and $"M" >= mThreshold, lit("重要发展"))
.when($"R" < rThreshold and $"F" >= fThreshold and $"M" < mThreshold, lit("一般保持"))
.when($"R" >= rThreshold and $"F" >= fThreshold and $"M" < mThreshold, lit("一般价值"))
.when($"R" < rThreshold and $"F" < fThreshold and $"M" < mThreshold, lit("一般挽留"))
.when($"R" >= rThreshold and $"F" < fThreshold and $"M" < mThreshold, lit("一般发展"))
.otherwise(lit("其他")) -
查看每个级别的用户数量
rfmWithLabelDF.groupBy("label").count().show() -
保存计算出来的结果
rfmWithLabelDF.write
.mode(SaveMode.Overwrite)
.option("header", value = true)
.csv("path/to/save")
差异
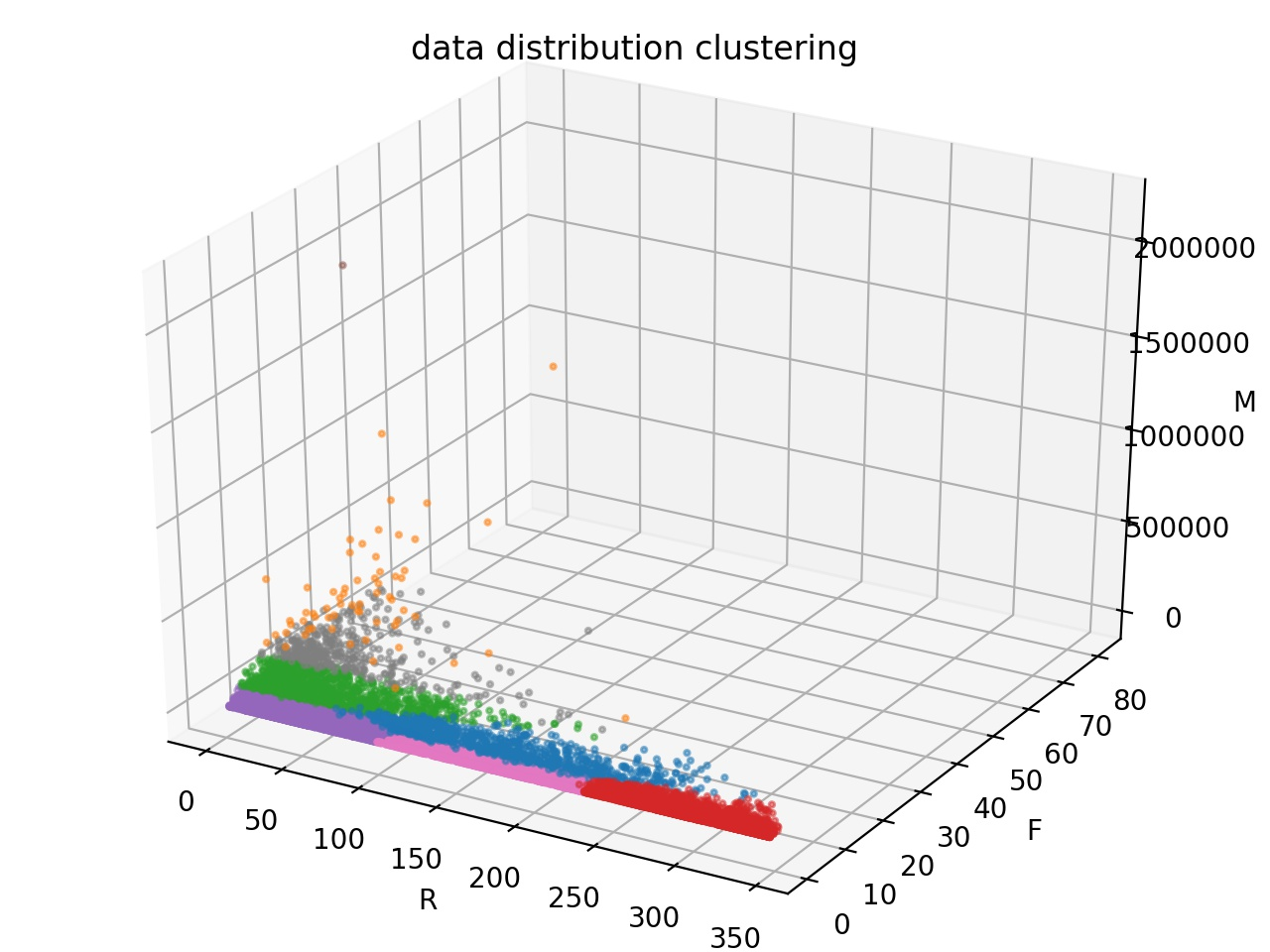
具体要选取哪种要根据业务本身的需求和数据的质量来决定。
更多
在使用聚类或者统计手段给用户分了类别之后,我们面临的新问题就是同一类别的数据有没有优先级?
答案肯定是有的,我们肯定是要对客户簇进行细分。
利用 AHP 法分析(The analytic hierarchy process)得到的 RFM 各指标权重,结合各类顾客的 RFM 指标,根据每一类客户的顾客终身价值得分来进行排序。
在进行客户分类后再对客户的类别进行顾客终身价值排序,使得企业能够量化各类客户的价值的差别,弥补了的客户分类方法的不足。这有助于企业制定更为可行的客户政策。由于受到成本的制约,电信企业不可能采取无差别的个性化服务,企业只能将资源集中在少数几类对企业重要的客户上。按照总得分的排列情况,企业应该优先将资源投放到总得分较高的客户身上。
那如何进行层次分析呢?请参考Spark 大数据入门清单:AHP法分析顾客终身价值得分
总结