在之前的两个示例(分类影评 和预测汽车燃油效率 )中,我们了解到在训练周期达到一定次数后,模型在验证数据上的准确率会达到峰值,然后便开始下降。
也就是说,模型会过拟合训练数据 。请务必学习如何处理过拟合。
尽管通常可以在训练集上实现很高的准确率,但我们真正想要的是开发出能够很好地泛化到测试数据(或之前未见过的数据)的模型。
与过拟合相对的是欠拟合。当测试数据仍存在改进空间 时,便会发生欠拟合。出现这种情况的原因有很多:模型不够强大、过于正则化,或者根本没有训练足够长的时间。这意味着网络未学习训练数据中的相关模式。
如果训练时间过长,模型将开始过拟合,并从训练数据中学习无法泛化到测试数据的模式。我们需要在这两者之间实现平衡。了解如何训练适当的周期 次数是一项很实用的技能,接下来我们将介绍这一技能。
为了防止发生过拟合,最好的解决方案是使用更多训练数据。用更多数据进行训练的模型自然能够更好地泛化 。
如无法采用这种解决方案,则次优解决方案是使用正则化等技术。这些技术会限制模型可以存储的信息的数量和类型。
如果网络只能记住少量模式,那么优化过程将迫使它专注于最突出的模式,因为这些模式更有机会更好地泛化。
在此文章中,我们将探索两种常见的正则化技术(权重正则化:kernel_regularizer 和 丢弃:Dropout ),并改进 IMDB 影评分类。
import tensorflow as tffrom tensorflow import kerasimport numpy as npimport matplotlib.pyplot as plt
我们将对句子进行多热编码 :multi_hot。该模型将很快过拟合训练集。演示何时发生过拟合,以及如何防止过拟合。
对列表进行多热编码,也就是说将转换为由 0 和 1 组成的向量 。例如,将序列 [3, 5] 转换为一个 10000 维的向量(除索引 3 和 5 转换为 1 之外,其余全为 0)。
array([0., 0., 0., 1., 0., 1, ....,])
NUM_WORDS = 10000 def multi_hot_sequences (sequences, dimension ):len (sequences), dimension))for i, word_indices in enumerate (sequences):1.0 return results
上面代码multi_hot_sequences函数,将train_data中每一条影评在新建的全零的np数组里面有数值位的全置为1.0
总共25000行,每行10000列,每行都大概类似于:
array([0., 0., 0., 1., 0., 1, ....,])
的一个二维np数组
如果是第一次运行上述代码,会显示以下的下载过程:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
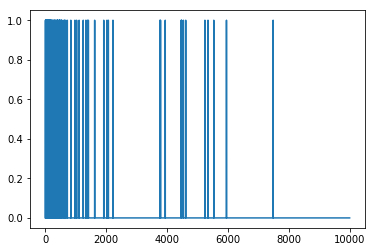
我们来看看生成的其中一个多热向量。
字词索引按频率排序,因此索引 0 附近应该有更多的 1 值,如下图所示:
要防止过拟合,最简单的方法是缩小模型 ,即减少模型中可学习参数的数量 (由层数和每层的单元数决定)。
在深度学习中,模型中可学习参数的数量通常称为模型的“容量”。直观而言,参数越多的模型“记忆容量”越大,因此能够轻松学习训练样本与其目标之间的字典式完美映射(无任何泛化能力的映射),但如果要对之前未见过的数据做出预测,这种映射毫无用处。
请务必谨记:深度学习模型往往善于与训练数据拟合,但真正的挑战是泛化,而非拟合。
另一方面,如果网络的记忆资源有限,便无法轻松学习映射。为了最小化损失,它必须学习具有更强预测能力的压缩表示法。同时,如果模型太小,它将难以与训练数据拟合。我们需要在“太多容量”和“容量不足”这两者之间实现平衡。
遗憾的是,并没有什么神奇公式可用来确定合适的模型大小或架构(由层数或每层的合适大小决定)。您将需要尝试一系列不同的架构。
要找到合适的模型大小,最好先使用相对较少的层和参数,然后开始增加层的大小或添加新的层,直到看到返回的验证损失不断减小为止。
我们将仅使用 Dense 层创建一个简单的基准模型,然后创建更小和更大的版本,并比较这些版本。
baseline_model = keras.Sequential([16 , activation=tf.nn.relu, input_shape=(NUM_WORDS,)),16 , activation=tf.nn.relu),1 , activation=tf.nn.sigmoid)compile (optimizer='adam' ,'binary_crossentropy' ,'accuracy' , 'binary_crossentropy' ])
_________________________________________________________________
fit model:
baseline_history = baseline_model.fit(train_data,20 ,512 ,2 )
Train on 25000 samples, validate on 25000 samples
smaller_model = keras.Sequential([4 , activation=tf.nn.relu, input_shape=(NUM_WORDS,)),4 , activation=tf.nn.relu),1 , activation=tf.nn.sigmoid)compile (optimizer='adam' ,'binary_crossentropy' ,'accuracy' , 'binary_crossentropy' ])
_________________________________________________________________
smaller_history = smaller_model.fit(train_data,20 ,512 ,2 )
Train on 25000 samples, validate on 25000 samples
bigger_model = keras.models.Sequential([512 , activation=tf.nn.relu, input_shape=(NUM_WORDS,)),512 , activation=tf.nn.relu),1 , activation=tf.nn.sigmoid)compile (optimizer='adam' ,'binary_crossentropy' ,'accuracy' ,'binary_crossentropy' ])
_________________________________________________________________
再次使用相同的数据训练该模型
bigger_history = bigger_model.fit(train_data, train_labels,20 ,512 ,2 )
Train on 25000 samples, validate on 25000 samples
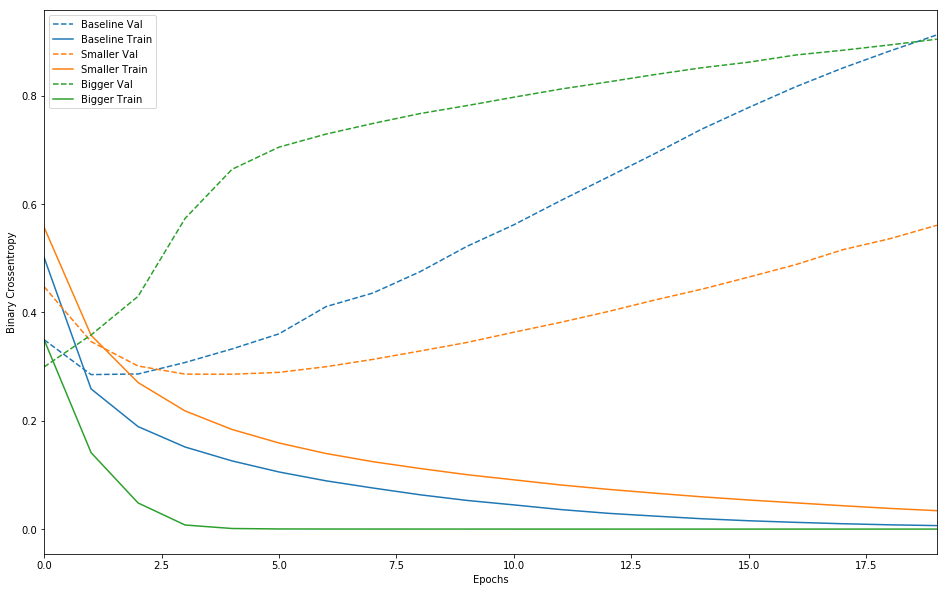
实线表示训练损失,虚线表示验证损失(请谨记:验证损失越低,表示模型越好)。在此示例中,较小的网络开始过拟合的时间比基准模型晚(前者在 6 个周期之后,后者在 4 个周期之后),并且开始过拟合后,它的效果下降速度也慢得多。
def plot_history (histories, key='binary_crossentropy' ):16 ,10 ))for name, history in histories:'val_' +key],'--' , label=name.title()+' Val' )0 ].get_color(),' Train' )'Epochs' )'_' ,' ' ).title())0 ,max (history.epoch)])'baseline' , baseline_history),'smaller' , smaller_history),'bigger' , bigger_history)])
较大的网络几乎仅仅 1 个周期之后便立即开始过拟合,并且之后严重得多。网络容量越大,便能够越快对训练数据进行建模(产生较低的训练损失),但越容易过拟合。
奥卡姆剃刀定律:如果对于同一现象有两种解释,最可能正确的解释是“最简单”的解释,即做出最少量假设的解释。
这也适用于神经网络学习的模型:给定一些训练数据和一个网络架构,有多组权重值(多个模型)可以解释数据,而简单模型比复杂模型更不容易过拟合。
在这种情况下,“简单模型”是一种参数值分布的熵较低的模型(或者具有较少参数的模型,如我们在上面的部分中所见)。因此,要缓解过拟合,一种常见方法是限制网络的复杂性 ,具体方法是**强制要求其权重仅采用较小的值,使权重值的分布更“规则”。**这称为“权重正则化”,通过向网络的损失函数添加与权重较大相关的代价来实现。这个代价分为两种类型:
L1 正则化,其中所添加的代价与权重系数的绝对值(即所谓的权重“L1 范数”)成正比。
L2 正则化,其中所添加的代价与权重系数值的平方(即所谓的权重“L2 范数”)成正比。L2 正则化在神经网络领域也称为权重衰减。不要因为名称不同而感到困惑:从数学角度来讲,权重衰减与 L2 正则化完全相同。
在 tf.keras
l2_model = keras.models.Sequential([16 , kernel_regularizer=keras.regularizers.l2(0.001 ),16 , kernel_regularizer=keras.regularizers.l2(0.001 ),1 , activation=tf.nn.sigmoid)compile (optimizer='adam' ,'binary_crossentropy' ,'accuracy' , 'binary_crossentropy' ])20 ,512 ,2 )
Train on 25000 samples, validate on 25000 samples
l2(0.001) 表示层的权重矩阵中的每个系数都会将 $0.001 \times w e i g h t c o e f f i c i e n t v a l u e weight_coefficient_value w e i g h t c o e f f i c i e n t v a l u e
以下是 L2 正则化惩罚的影响:
plot_history([('baseline' , baseline_history),'l2' , l2_model_history)])
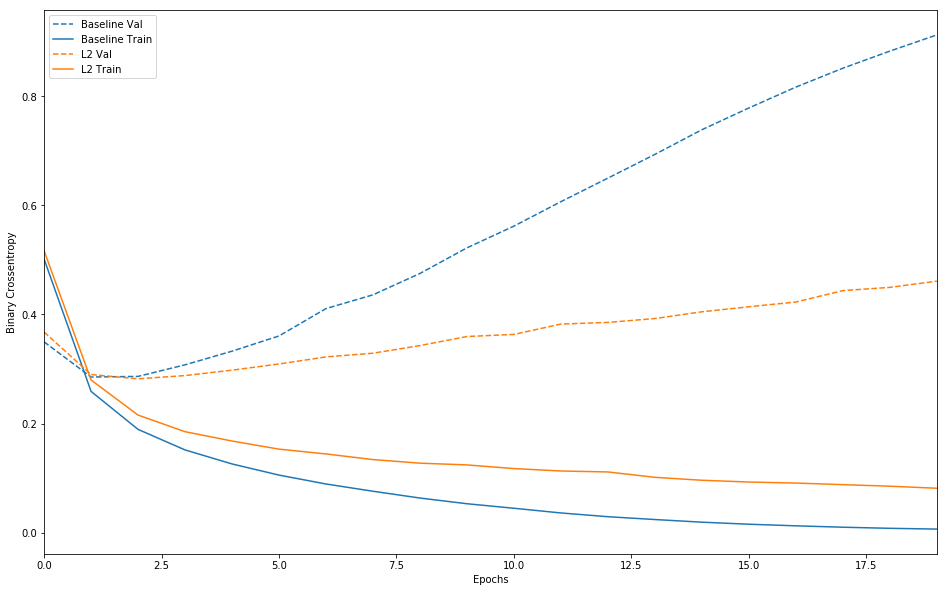
可以看到,L2 正则化模型的过拟合抵抗能力比基准模型强得多,虽然这两个模型的参数数量相同。
丢弃是由 Hinton 及其在多伦多大学的学生开发的,是最有效且最常用的神经网络正则化技术之一。丢弃(应用于某个层)是指在训练期间随机“丢弃” (即设置为 0)该层的多个输出特征。
假设某个指定的层通常会在训练期间针对给定的输入样本返回一个向量[0.2, 0.5, 1.3, 0.8, 1.1];在应用丢弃后,此向量将随机分布几个 0 条目,例如[0, 0.5, 1.3, 0, 1.1]。“丢弃率”指变为 0 的特征所占的比例,通常设置在 0.2 和 0.5 之间。
在测试时,网络不会丢弃任何单元,而是将层的输出值按等同于丢弃率的比例进行缩减,以便平衡以下事实:测试时的活跃单元数大于训练时的活跃单元数。
在 tf.keras 中,您可以通过丢弃层将丢弃引入网络中,以便事先将其应用于层的输出。
下面我们在 IMDB 网络中添加两个丢弃层,看看它们在降低过拟合方面表现如何:
dpt_model = keras.models.Sequential([16 , activation=tf.nn.relu, input_shape=(NUM_WORDS,)),0.5 ),16 , activation=tf.nn.relu),0.5 ),1 , activation=tf.nn.sigmoid)compile (optimizer='adam' ,'binary_crossentropy' ,'accuracy' ,'binary_crossentropy' ])20 ,512 ,2 )
Train on 25000 samples, validate on 25000 samples
plot_history([('baseline' , baseline_history),'dropout' , dpt_model_history)])
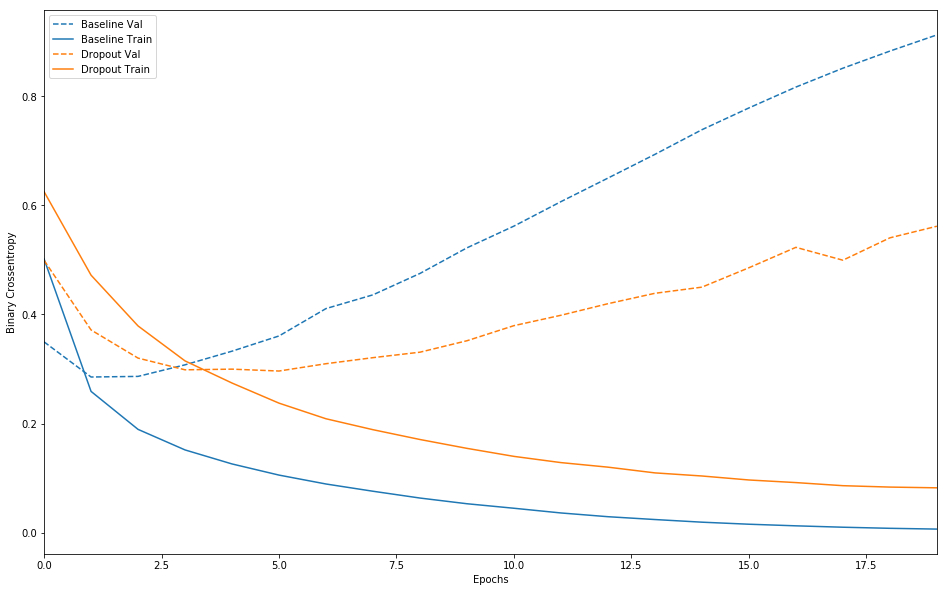
添加丢弃层可明显改善基准模型。
下面总结一下防止神经网络出现过拟合的最常见方法:
获取更多训练数据。
降低网络容量。
添加权重正则化。
添加丢弃层。
还有两个重要的方法:数据增强和批次归一化。
数据增强解决你有限的数据集。
在神经网络中,每一层的输入在经过层内操作之后必然会导致与原来对应的输入信号分布不同,并且前层神经网络的增加会被后面的神经网络不对的累积放大。
这个问题的一个解决思路就是根据训练样本与目标样本的比例对训练样本进行一个矫正,而BN算法(批标准化)则可以用来规范化某些层或者所有层的输入,从而固定每层输入信号的均值与方差。
keras.layers.normalization.BatchNormalization(epsilon=1e-6 , weights=None )
归一化能够对输入输出进行归一化操作的结构层,将前一层的激活输出按照数据batch进行归一化。
在每一个批次的数据中标准化前一层的激活项, 即,应用一个维持激活项平均值接近 0,标准差接近 1 的转换。
inputshape: 任意。当把该层作为模型的第一层时,必须使用该参数(是一个整数元组,不包括样本维度)
outputshape: 同input shape一样。
参数:
epsilon: small float > 0,Fuzz parameter。weights: 初始化权值。含有2个numpy arrays的list,其shape是[(input_shape,), (input_shape,)]
input_points = Input(shape=(2048 , 3 ))64 , 1 , activation='relu' )(input_points)128 , 1 , activation='relu' )(x)1024 , 1 , activation='relu' )(x)2048 )(x)512 , activation='relu' )(x)256 , activation='relu' )(x)9 , weights=[np.zeros([256 , 9 ]), np.array([1 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 1 ]).astype(np.float32)])(x)3 , 3 ))(x)64 , 1 , activation='relu' )(g)64 , 1 , activation='relu' )(g)64 , 1 , activation='relu' )(g)128 , 1 , activation='relu' )(f)1024 , 1 , activation='relu' )(f)2048 )(f)512 , activation='relu' )(f)256 , activation='relu' )(f)64 * 64 , weights=[np.zeros([256 , 64 * 64 ]), np.eye(64 ).flatten().astype(np.float32)])(f)64 , 64 ))(f)64 , 1 , activation='relu' )(g)128 , 1 , activation='relu' )(g)1024 , 1 , activation='relu' )(g)2048 )(g)512 , activation='relu' )(global_feature)0.5 )(c)256 , activation='relu' )(c)0.5 )(c)'softmax' )(c)
就是在每一层的后面再加上一层BatchNormalization
减少了参数的人为选择,可以取消dropout和L2正则项参数,或者采取更小的L2正则项约束参数
减少了对学习率的要求
可以不再使用局部响应归一化了,BN本身就是归一化网络(局部响应归一化-AlexNet)
更破坏原来的数据分布,一定程度上缓解过拟合。