回归问题的目标是预测一系列连续值的输出,比如价格和概率。和分类问题不一样,分类问题是从一堆中选出一类。(比方说从一堆照片中选出带有苹果的照片等)
这篇文章使用 Auto MPG 数据集来构建模型,预测上世纪70年到80年代的汽车燃油效率。这些数据包含:气缸 、排量 、马力 和重量 等属性。
我们需要使用seaborn来绘制一些图像:
首次运行上述代码时:
Collecting seaborn
引入此项目使用的依赖库
from __future__ import absolute_import, division, print_functionimport pathlibimport pandas as pdimport seaborn as snsimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers
输出tensorflow版本如下:
数据集来自UCI Machine Learning Repository
MPG 意为 Miles per Gallon ,衡量一辆汽车 在你的油箱中只加一加仑汽油或柴油可以行驶多少英里。
首先,使用keras下载数据
dataset_path = keras.utils.get_file("auto-mpg.data" , "https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data" )
输出auto-mpg.data文件存放地址:
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data
使用pandas引入数据集
column_names = ['MPG' ,'Cylinders' ,'Displacement' ,'Horsepower' ,'Weight' ,'Acceleration' , 'Model Year' , 'Origin' ] "?" , comment='\t' ," " , skipinitialspace=True )
na_values = "?":na 意为 not available ,即不可用 。
dataset.tail()输出最后5行,你也可以执行dataset.tail(10)来输出10行或自定义一个数字,来观察表格数据。
MPG
Cylinders
Displacement
Horsepower
Weight
Acceleration
Model Year
Origin
393
27.0
4
140.0
86.0
2790.0
15.6
82
1
394
44.0
4
97.0
52.0
2130.0
24.6
82
2
395
32.0
4
135.0
84.0
2295.0
11.6
82
1
396
28.0
4
120.0
79.0
2625.0
18.6
82
1
397
31.0
4
119.0
82.0
2720.0
19.4
82
1
经过pands处理,?变成了NaN
数据集某些行有几个?的值
使用pandas来统计一下这些值的数量:
其中isna()意为is not available
MPG 0
为了简单起见,我们删除这些数据不完整的行:
dataset = dataset.dropna()
Origin列代表汽车的产地,1代表美国,2代表欧洲,3代表日本,为了学习方便,我们把它转化为相应的列,是为1,不是为0
首先,删除Origin列,将它存到变量origin里
origin = dataset.pop('Origin' )
然后,进项判断,添加到新的列里面去
dataset['USA' ] = (origin == 1 )*1.0 'Europe' ] = (origin == 2 )*1.0 'Japan' ] = (origin == 3 )*1.0
注意:True==1.000000000000001(小数点后15位)的结果是False,True==1.0000000000000001(小数点后16位)的结果是True
MPG
Cylinders
Displacement
Horsepower
Weight
Acceleration
Model Year
USA
Europe
Japan
393
27.0
4
140.0
86.0
2790.0
15.6
82
1.0
0.0
0.0
394
44.0
4
97.0
52.0
2130.0
24.6
82
0.0
1.0
0.0
395
32.0
4
135.0
84.0
2295.0
11.6
82
1.0
0.0
0.0
396
28.0
4
120.0
79.0
2625.0
18.6
82
1.0
0.0
0.0
397
31.0
4
119.0
82.0
2720.0
19.4
82
1.0
0.0
0.0
把数据集分割为训练集和测试集。
测试集在最后验证评估的时候使用。
train_dataset = dataset.sample(frac=0.8 ,random_state=0 )
frac=0.8 Fraction 代表80%,如果是n=320,代表320个。ps: n和frac不可同时使用
random_state随机数生成器的种子数
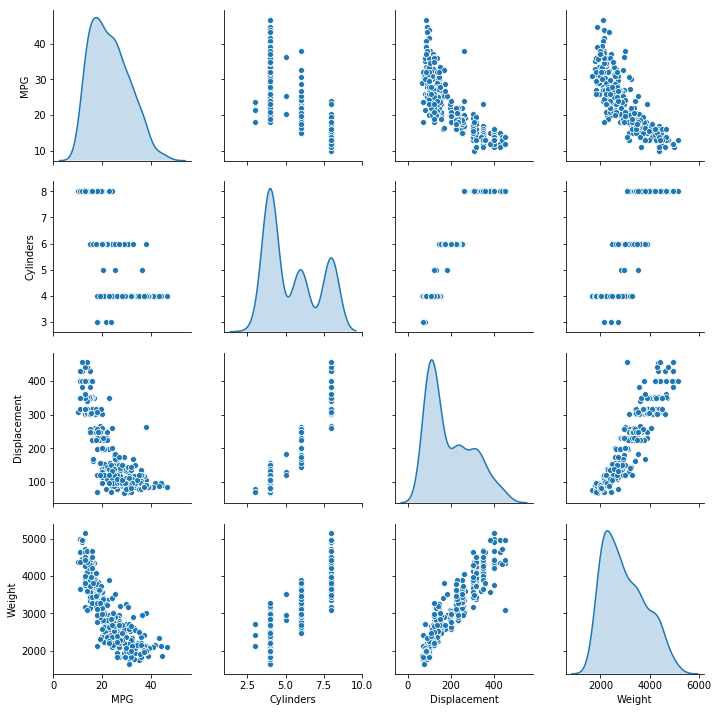
使用seaborn观察数据分布情况
关于sns.pairplot的文档请参阅https://seaborn.pydata.org/generated/seaborn.pairplot.html
sns.pairplot(train_dataset[["MPG" , "Cylinders" , "Displacement" , "Weight" ]], diag_kind="kde" )
再看看数据统计:
train_stats = train_dataset.describe()"MPG" )
count
mean
std
min
25%
50%
75%
max
Cylinders
314.0
5.477707
1.699788
3.0
4.00
4.0
8.00
8.0
Displacement
314.0
195.318471
104.331589
68.0
105.50
151.0
265.75
455.0
Horsepower
314.0
104.869427
38.096214
46.0
76.25
94.5
128.00
225.0
Weight
314.0
2990.251592
843.898596
1649.0
2256.50
2822.5
3608.00
5140.0
Acceleration
314.0
15.559236
2.789230
8.0
13.80
15.5
17.20
24.8
Model Year
314.0
75.898089
3.675642
70.0
73.00
76.0
79.00
82.0
USA
314.0
0.624204
0.485101
0.0
0.00
1.0
1.00
1.0
Europe
314.0
0.178344
0.383413
0.0
0.00
0.0
0.00
1.0
Japan
314.0
0.197452
0.398712
0.0
0.00
0.0
0.00
1.0
其中count 代表总数量 ,mean代表均值 ,std代表标准差 (standard deviation) ,min代表最小值 ,max代表最大值
25%代表 一分位数 (一分位数:1/4,二分位数:2/4,以此类推)。
以排量举例,上表Displacement中:25%的汽车小于105.5的排量,50%的汽车小于151.0的排量,75%的汽车小于265.75的排量,以此类推
MPG值是我们训练模型来预测的值,所以要将其从数据集中提取出来作为labels
train_labels = train_dataset.pop('MPG' )'MPG' )
从train_stats表格里面的数据,我们可以看出数据特征范围的差异性有多大。
标准分数 (Standard Score,又称z-score ,中文称为Z-分数 或标准化值 )
z = x − μ 2 σ . z = {x-\mu\over 2\sigma}.
z = 2 σ x − μ .
x x x μ \mu μ 平均值 σ \sigma σ 标准差
如果数据太过随机,没有特征或特征不规律,会使得训练变难,使训练结果过度依赖原始数据的随机特征。
尽管train_stats是从训练集中统计的,但还是可以重复利用之
def norm (x ):return (x - train_stats['mean' ]) / train_stats['std' ]
让我们再来看看标准化处理过的数据长什么样子:
normed_train_data.describe().transpose()
count
mean
std
min
25%
50%
75%
max
Cylinders
314.0
1.824443e-16
1.0
-1.457657
-0.869348
-0.869348
1.483887
1.483887
Displacement
314.0
8.627211e-17
1.0
-1.220325
-0.860894
-0.424785
0.675074
2.489002
Horsepower
314.0
-9.900078e-18
1.0
-1.545283
-0.751241
-0.272190
0.607162
3.153347
Weight
314.0
-8.485781e-17
1.0
-1.589352
-0.869478
-0.198782
0.732017
2.547401
Acceleration
314.0
-5.148041e-16
1.0
-2.710152
-0.630725
-0.021237
0.588250
3.313017
Model Year
314.0
9.772791e-16
1.0
-1.604642
-0.788458
0.027726
0.843910
1.660094
USA
314.0
7.920062e-17
1.0
-1.286751
-1.286751
0.774676
0.774676
0.774676
Europe
314.0
1.980016e-17
1.0
-0.465148
-0.465148
-0.465148
-0.465148
2.143005
Japan
314.0
5.374328e-17
1.0
-0.495225
-0.495225
-0.495225
-0.495225
2.012852
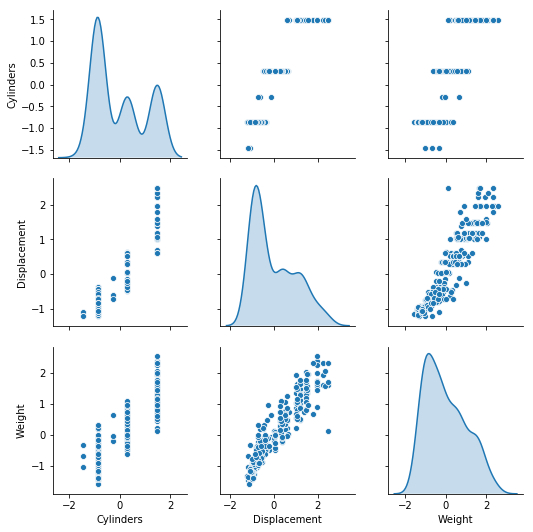
可以明显看到,数据均值为0,标准差为1
使用seaborn观察经过标准化处理的数据分布情况:
sns.pairplot(normed_train_data[["Cylinders" , "Displacement" , "Weight" ]], diag_kind="kde" )
我们使用Sequential模型,添加两个全连接的Dense layers,一个大小为1的Dense layer,作为预测结果。
并用函数build_model包裹起来,因为后文我们还要再创建一个模型。
def build_model ():64 , activation=tf.nn.relu, input_shape=[len (train_dataset.keys())]),64 , activation=tf.nn.relu),1 )0.001 )compile (loss='mse' ,'mae' , 'mse' ])return model
使用summary()方法,打印简单的模型信息
_________________________________________________________________
现在,取前10个样本来做预测尝试看看程序是否能正确运行:
example_batch = normed_train_data[:10 ]
array([[-0.00998245],
虽然值不正确,但产生了期待的数据类型,说明我们的模型的对的。
训练1000批次,同时记录下训练和验证的准确率。
class PrintDot (keras.callbacks.Callback ):def on_epoch_end (self, epoch, logs ):if epoch % 100 == 0 : print('' )'.' , end='' )1000 0.2 , verbose=0 ,
....................................................................................................
利用pandas把训练记录可视化:
hist = pd.DataFrame(history.history)'epoch' ] = history.epoch
loss
mean_absolute_error
mean_squared_error
val_loss
val_mean_absolute_error
val_mean_squared_error
epoch
995
2.838588
1.055799
2.838588
9.635040
2.360446
9.635040
995
996
2.627797
1.077834
2.627797
10.011816
2.454931
10.011816
996
997
2.791595
1.062792
2.791595
9.421341
2.350526
9.421341
997
998
2.828236
1.110399
2.828236
9.730920
2.364439
9.730920
998
999
2.727029
1.034335
2.727029
9.779824
2.373134
9.779824
999
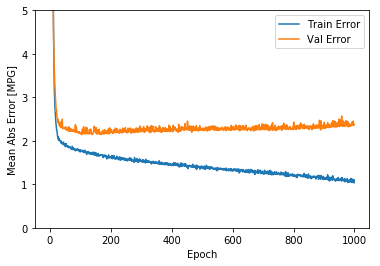
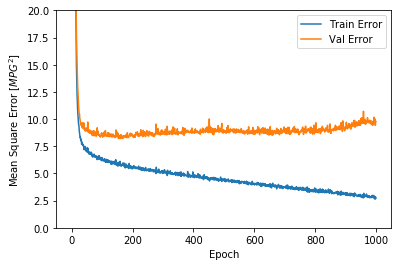
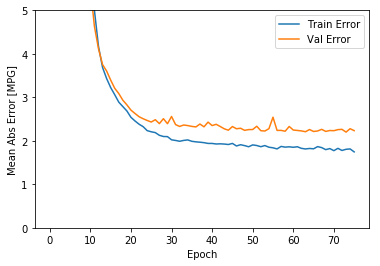
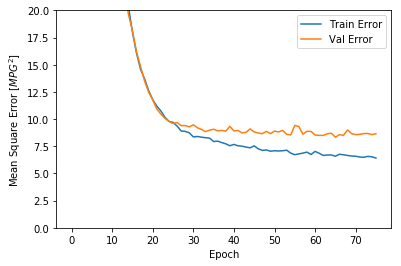
import matplotlib.pyplot as pltdef plot_history (history ):'epoch' ] = history.epoch'Epoch' )'Mean Abs Error [MPG]' )'epoch' ], hist['mean_absolute_error' ],'Train Error' )'epoch' ], hist['val_mean_absolute_error' ],'Val Error' )0 ,5 ])'Epoch' )'Mean Square Error [$MPG^2$]' )'epoch' ], hist['mean_squared_error' ],'Train Error' )'epoch' ], hist['val_mean_squared_error' ],'Val Error' )0 ,20 ])
这两张图表明,在大概100多个批次之后,错误率降低的太少了,甚至验证错误率还稍稍上升了一些。
我们需要在适当的时候使用EarlyStopping回调函数来测试每个批次的训练条件,如果经过一定数量的批次,还没有改进,则自动停止训练。
您可以在此处 了解有关此回调的更多信息。
model = build_model()'val_loss' , patience=10 )0.2 , verbose=0 , callbacks=[early_stop, PrintDot()])
............................................................................
现在,大概验证的错误率是 $\pm2 $ 多一点。
我们使用它来进行预测吧。测试集没有参与训练,测试集的测试结果将会向我们展示训练的模型在实际中效果如何。
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=0 )"Testing set Mean Abs Error: {:5.2f} MPG" .format (mae))
Testing set Mean Abs Error: 1.84 MPG
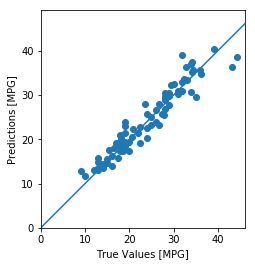
test_predictions = model.predict(normed_test_data).flatten()'True Values [MPG]' )'Predictions [MPG]' )'equal' )'square' )0 ,plt.xlim()[1 ]])0 ,plt.ylim()[1 ]])100 , 100 ], [-100 , 100 ])
这张图x坐标代表实际值,y坐标代表预测值,所以当点越集中在中间那条反对角线的时候,说明预测越准。
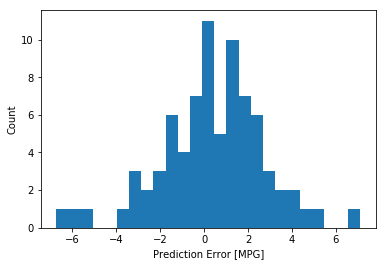
看看错误的分布情况
error = test_predictions - test_labels25 )"Prediction Error [MPG]" )"Count" )
有点正态分布的意思,但是不严格,因为数据量确实太少了。
均方误差(MSE)是用于回归问题的常见损失函数。
用于回归的评估指标,常见的回归度量是平均绝对误差(MAE)。
当数字输入数据要素具有不同范围的值时,应将每个特征独立地缩放到相同范围。
如果没有太多的训练数据,创建一个隐藏层少的小网络,以避免过度拟合。
早期停止是防止过拟合的有用技术。
你可以在这里:https://github.com/HarborZeng/fuel_efficiency 找到和本文一样的Jupyter Notebook代码,进行学习。更多Jupyter Notebook的用法,请参考:https://jupyter.org/