
Abstract 摘要
Mining frequent patterns in transaction databases, time-series databases, and many other kinds of databases has been studied popularly in data mining research. 在数据挖掘研究中普遍研究了在事务数据库,时间序列数据库和许多其他类型的数据库中挖掘频繁模式。Most of the previous studies adopt an Apriori-like candidate set generation-and-test approach. 大多数先前的研究采用类似Apriori的候选集生成和测试方法。However, candidate set generation is still costly, especially when there exist prolific patterns and/or long patterns. 然而,候选集生成仍然花销巨大,尤其是存在多产模式和/或长模式时。
In this study, we propose a novel frequent pattern tree (FP-tree) structure, which is an extended prefix tree structure for storing compressed, crucial information about frequent patterns, and develop an efficient FP-tree-based mining method, FP-growth, for mining the complete set of frequent patterns by pattern fragment growth. 在这项研究中,我们提出了一种新的频繁模式树(FP-tree)结构,它是一种扩展的前缀树结构,用于存储关于频繁模式的压缩的关键信息,并开发一种有效的基于FP树的挖掘方法,FP-growth ,用于通过模式片段增长挖掘整套频繁模式。Efficiency of mining is achieved with three techniques: (1) a large database is compressed into a highly condensed, much smaller data structure, which avoids costly, repeated database scans, (2) our FP-tree-based mining adopts a pattern fragment growth method to avoid the costly generation of a large number of candidate sets, and (3) a partitioning-based, divide-and-conquer method is used to decompose the mining task into a set of smaller tasks for mining confined patterns in conditional databases, which dramatically reduces the search space. Our performance study shows that the FP-growth method is efficient and scalable for mining both long and short frequent patterns, and is about an order of magnitude faster than the Apriori algorithm and also faster than some recently reported new frequent pattern mining methods. 采用三种技术实现了挖掘的效率:(1)将大型数据库压缩成高度压缩,小得多的数据结构,避免了昂贵的,重复的数据库扫描。(2)我们基于FP树的挖掘采用了模式片段生长方法, 以避免昂贵的大量候选集的生成,以及(3)基于分区的,分而治之的方法用于将挖掘任务分解为一组较小的任务,用于在条件数据库中挖掘受限模式,这大大减少了搜索空间。我们的性能研究表明,FP-growth方法对于挖掘长和短频繁模式是有效和可扩展的,并且比Apriori算法快一个数量级,并且比最近报告的一些新的频繁模式挖掘方法更快。
Introduction 介绍
这一章的主要内容就是 diss 一下 Apriori 这个传统算法,然后简单介绍一下自己的算法是怎么解决 Apriori 的固有缺陷。就简单挑几句有用的翻译一下吧。
作者说他提出来的方法,大概是这样工作的:
First, a novel, compact data structure, called frequent pattern tree, or FP-tree for short, is constructed, which is an extended prefix-tree structure storing crucial, quantitative information about frequent patterns. 首先,构造了一种新颖,紧凑的数据结构,称为频繁模式树,或简称FP树,它是一种扩展的前缀树结构,存储关于频繁模式的关键的定量信息。Only frequent length-1 items will have nodes in the tree, and the tree nodes are arranged in such a way that more frequently occurring nodes will have better chances of sharing nodes than less frequently occurring ones. 只有频繁的长度为1的项目将在树中具有节点,并且树节点的排列方式使得更频繁出现的节点比不常出现的节点具有更好的共享节点的机会。
Second, an FP-tree-based pattern fragment growth mining method, is developed, which starts from a frequent length-1 pattern (as an initial suffix pattern), examines only its conditional pattern base (a sub-database" which consists of the set of frequent items co-occurring with the suffix pattern), constructs its (conditional) FP-tree, and performs mining recursively with such a tree. 其次,开发了一种基于FP树的模式片段增长挖掘方法,该方法从频繁的长度为1的模式(作为初始后缀x模式)开始, 仅检查其条件模式库(“子数据库”,其由与suffix模式共同出现的频繁项集合),构造其(条件)FP树,并用这样的树递归地执行挖掘。The pattern growth is achieved via concatenation of the suffix pattern with the new ones generated from a conditional FP-tree. 通过串联后缀模式与从条件FP树生成的新模式的连接来实现模式增长。Since the frequent itemset in any transaction is always encoded in the corresponding path of the frequent pattern trees, pattern growth ensures the completeness of the result. 由于任何事务中的频繁项集总是在频繁模式树的相应路径中编码,因此模式增长确保了结果的完整性。In this context, our method is not Apriori-like restricted generation-and-test but restricted test only. 在这种情况下,我们的方法不是Apriori式限制生成和测试,而是仅限制测试。The major operations of mining are count accumulation and prefix path count adjustment, which are usually much less costly than candidate generation and pattern matching operations performed in most Apriori-like algorithms. 挖掘的主要操作是计数累积和前缀路径计数调整,这通常比在大多数类Apriori算法中执行的候选生成和模式匹配操作成本低得多。
Third, the search technique employed in mining is a partitioning-based, divide-and-conquer method rather than Apriori-like bottom-up generation of frequent itemsets combinations. 第三,挖掘中使用的搜索技术是基于分区的: 分而治之的方法,而不是类似Apriori的自下而上的频繁项集组合。This dramatically reduces the size of conditional pattern base generated at the subsequent level of search as well as the size of its corresponding conditional FP-tree. 这大大减小了在后续搜索级别生成的条件模式库的大小以及其对应的条件FP 树的大小。Moreover, it transforms the problem of finding long frequent patterns to looking for shorter ones and then concatenating the suffix. 此外,它将寻找较长频繁模式的问题转换为寻找较短模式然后连接后缀的问题。It employs the least frequent items as suffix, which offers good selectivity. All these techniques contribute to substantial reduction of search costs. 它使用最不频繁的项目作为后缀,这提供了良好的选择性。所有这些技术都有助于大幅降低搜索成本。
然后后面就是各种对比,说自己的方法多么多么快,就是论文的一般套路。
Frequent Pattern Tree: Design and Construction 频繁模式树:设计与构建
下表是某超市的部分销售记录,每一条是顾客购买的东西集合,第三列表示第二列中频繁出现的物品。有几点需要预先约定好:
- Since only the frequent items will play a role in the frequent pattern mining, it is necessary to perform one scan of DB to identify the set of frequent items (with frequency count obtained as a by-product). 由于只有频繁项目在频繁模式挖掘中起作用, 因此必须执行一次DB扫描以识别频繁项目集合。
- If we store the set of frequent items of each transaction in some compact structure, it may avoid repeatedly scanning of DB. 如果我们将每个交易的频繁项目集存储在一些紧凑的结构中,则可以避免重复扫描DB。
- If multiple transactions share an identical frequent item set, they can be merged into one with the number of occurrences registered as count. It is easy to check whether two sets are identical if the frequent items in all of the transactions are sorted according to a fixed order. 如果多个交易共享相同的频繁项集,则可以将它们合并为一个具有注册为计数的事件数。如果所有交易中的频繁项目按固定顺序排序,则很容易检查两个集合是否相同。
- If two transactions share a common prefix, according to some sorted order of frequent items, the shared parts can be merged using one prefix structure as long as the count is registered properly. If the frequent items are sorted in their frequency descending order, there are better chances that more prefix strings can be shared. 如果两个事务共享一个公共前缀,则根据频繁项的某些排序顺序,只要计数被正确注册,就可以使用一个前缀结构合并共享部分。如果频繁项目按其频率降序排序,则更有可能共享更多前缀字符串。
| TID | Items Bought | (Ordered) Frequent Items |
|---|---|---|
| 100 | f ; a; c; d; g; i; m; p | f ; c; a; m; p |
| 200 | a; b; c; f ; l; m; o | f ; c; a; b; m |
| 300 | b; f ; h; j; o | f; b |
| 400 | b; c; k; s; p | c; b; p |
| 500 | a; f ; c; e; l; p; m; n | f ; c; a; m; p |
下图展示了构建一棵频繁模式树:
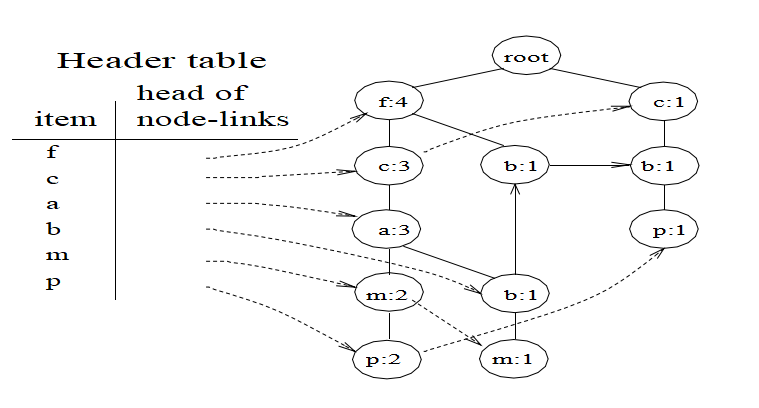
- It consists of one root labeled as “null”, a set of item prefix subtrees as the children of the root, and a frequent-item header table. 它由一个标记为“null”的根,一组前缀子树作为根的子项和一个频繁项头表组成。
- Each node in the item prefix subtree consists of three fields: item-name, count, and node- link, where item-name registers which item this node represents, count registers the number of transactions represented by the portion of the path reaching this node, and node-link links to the next node in the FP-tree carrying the same item-name, or null if there is none. 前缀子树中的每个节点由item-name , count和node-link三个字段组成,其中item- name注册该节点表示的项,count表示由到达此节点的路径部分表示的事务数。 node和node-link 链接到FP-tree 中携带相同item-name的下一个节点,如果没有则返回null。
- Each entry in the frequent-item header table consists of two fields, (1) item-name and (2) head of node-link, which points to the first node in the FP-tree carrying the item-name. 频繁项目标题表中的每个条目包括两个字段,(1)项目名称和(2)节点链接头部, 其指向携带项目名称的FP树中的第一个节点。
由此引入算法1:
Input: A transaction database DB and a minimum support threshold. 输入:事务数据库DB和最小支持阈值。
Output: Its frequent pattern tree, FP-tree 输出:它的频繁模式树,FP-tree
Method: The FP-tree is constructed in the following steps. 方法:FP-tree按以下步骤构建。
-
Scan the transaction database DB once. 扫描事务数据库DB一次。Collect the set of frequent items F and their supports. 收集频繁项目F及其支持。Sort F in support descending order as L, the list of frequent items. 1.按支持降序排序F为L,频繁项目列表。
-
Create the root of an FP-tree, T , and label it as “null”. For each transaction T Trans in DB do the following. 创建FP树的根T,并将其标记为“null”。对于DB中的每个事务,执行以下操作。
Select and sort the frequent items in T Trans according to the order of L. 根据L的顺序选择和排序T中的频繁项目。Let the sorted frequent item list in T Trans be [p|P], where p is the first element and P is the remaining list. Call insert_tree([p|P], T). 让T中的排序频繁项目列表为[p|P],其中p为第一个元素,P是剩余列表。调用insert_tree([p|P], T)。
The function insert_tree([p|P], T ) is performed as follows. If T has a child N such that N.item-name = p.item-name, then increment N 's count by 1; else create a new node N , and let its count be 1, its parent link be linked to T , and its node-link be linked to the nodes with the same item-name via the node-link structure. If P is nonempty, call insert tree(P, N ) recursively. 如果 T有一个孩子N那么N.item-name = p.item-name,然后将N的计数递增1; 否则创建一个新节点N,并将其计数为1,将其父链接链接到T,并通过节点链接结构将其节点链接链接到具有相同项目名称的节点。如果P为非空,则递归调用insert_tree([p|P], T )。
Mining Frequent Patterns using FP-tree
常见的关联规则算法主要有Apriori算法、FP-growth算法,FP-growth是一种不产生候选模式而采用频繁模式增长的方法挖掘频繁模式的算法;此算法只扫描两次,第一次扫描数据是得到频繁项集,第二次扫描是利用支持度过滤掉非频繁项,同时生成FP-Tree。然后后面的模式挖掘就是在这棵树上进行。此算法与Apriori算法最大不同的有两点:不产生候选集,只遍历两次数据,大大提升了效率。[1]
FP-growth算法为了减少I/O操作,提高效率,引入了一些数据结构存储数据,主要包括项头表、FP-Tree和节点链表。项头表(Header Table)即找出频繁1项集,删除低于支持度的项集,并按照出现的次数降序排序,这是第一次扫描数据。然后从数据中删除非频繁1项集,并按照项头表的顺序排序,这是第二次也是最后一次扫描数据。FP-Tree (Frequent Pattern Tree)初始时只有一个根节点Null,将每一条数据里的每一项,按照排序后的顺序插入FP-Tree,节点的计数为1,如果有共用的祖先,则共用祖先的节点计数 + 1。FP-Tree的挖掘过程如下,从长度为1的频繁模式开始挖掘。可以分为3个步骤:[1:1]
-
构造它的条件模式基(CPB, Conditional Pattern Base),条件模式基(CPB)就是我们要挖掘的Item的前缀路径;
-
然后构造它的条件FP-Tree (Conditional FP-tree);
-
递归的在条件FP-Tree上进行挖掘。
伪代码如下:[1:2]
|
FP-growth 函数的输入:tree 是指原始的 FP-Tree 或者是某个模式的条件 FP-Tree ,a 是指模式的后缀(在第一次调用时a = NULL,在之后的递归调用中a是模式后缀);[1:3]
FP-growth 函数的输出:在递归调用过程中输出所有的模式及其支持度。每一次调用 FP-growth 输出结果的模式中一定包含 FP-growth 函数输入的模式后缀。[1:4]
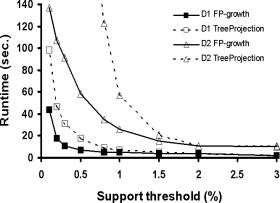
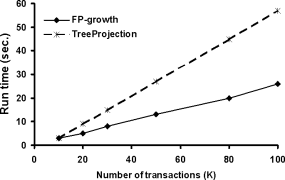
后面尽是一些和 Apriori 算法的一些性能比较,大致像这样:
结论
We have proposed a novel data structure, frequent pattern tree (FP-tree), for storing compressed, crucial information about frequent patterns, and developed a pattern growth method, FP-growth, for efficient mining of frequent patterns in large databases.
我们提出了一种新颖的数据结构,即频繁模式树(FP-tree),用于存储关于频繁模式的压缩的关键信息, 并开发了一种模式增长方法 FP- growth,用于有效挖掘大型数据库中的频繁模式。
与其他方法相比,FP增长有几个优点:There are several advantages of FP-growth over other approaches:
(1) It constructs a highly com- pact FP-tree, which is usually substantially smaller than the original database, and thus saves the costly database scans in the subsequent mining processes. 它构建了一个高度紧凑的FP树,通常比原始数据库小得多,从而节省了后续挖掘过程中昂贵的数据库扫描。
(2) It applies a pattern growth method which avoids costly candidate generation and test by successively concatenating frequent 1-itemset found in the (conditional) FP-trees : In this context, mining is not Apriori-like (restricted) generation-and-test but frequent pattern (fragment) growth only. The major operations of mining are count accumulation and prefix path count adjustment, which are usually much less costly than candidate generation and pattern match- ing operations performed in most Apriori-like algorithms.采用避免的模式增长方法通过连续连接(条件)FP树中发现的频繁1项集来进行昂贵的候选生成和测试:在这种情况下,挖掘不是类 Apriori(限制)生成和测试,而是频繁模式(片段)增长。挖掘的主要操作是计数累积和前缀路径计数调整,这通常比在大多数类Apriori算法中执行的候选生成和模式匹配操作成本低得多。
(3)It applies a partitioning-based divide- and-conquer method which dramatically reduces the size of the subsequent conditional pattern bases and conditional FP-trees. Several other optimization techniques, including direct pattern generation for single tree-path and employing the least frequent events as suffix, also contribute to the efficiency of the method. 它应用基于分区的分割和处理方法,它大大 减小了后续条件模式库和条件FP树的大小。其他几 种优化技术,包括单树路径的直接模式生成和使用 最少频率事件作为后缀x,也有助于该方法的效率。
We have implemented the FP-growth method, stud- ied its performance in comparison with several influential frequent pattern mining algorithms in large databases. Our performance study shows that the method mines both short and long patterns efficiently in large databases, outperforming the current candidate pattern generation-based algorithms. The FP-growth method has also been implemented in the new version of DBMiner system and been tested in large industrial databases, such as in London Drugs databases, with satisfactory performance
我们已经实现了FP-growth方法,研究了它与大型 数据库中几种有影响的频繁模式挖掘算法的性能。我们的性能研究表明,该方法在大型数据库中有效地挖掘短模式和长模式,优于当前基于候选模式生成的算法。FP-growth方法也已在新版本的DBMiner系统中实施,并在大型工业数据库(如伦敦药物数据库)中进行了测试,性能令人满意。
There are a lot of interesting research issues related to FP-tree-based mining, including further study and implementation of SQL-based, highly scalable FP-tree structure, constraint-based mining of frequent patterns using FP-trees, and the extension of the FP-tree-based mining method for mining sequential patterns, max-patterns, partial periodicity, and other interesting frequent patterns.
有许多与基于FP树的挖掘相关的有趣研究问题, 包括进一步研究和实现基于SQL的,高度可扩展的FP树结构,基于约束的使用FP树的频繁模式挖掘, 以及基于FP树的挖掘序列模式挖掘方法,最大模式,部分周期和其他有趣的频繁模式。




