首先,前往官网下载系统所匹配的版本
https://neo4j.com/download-center/#community
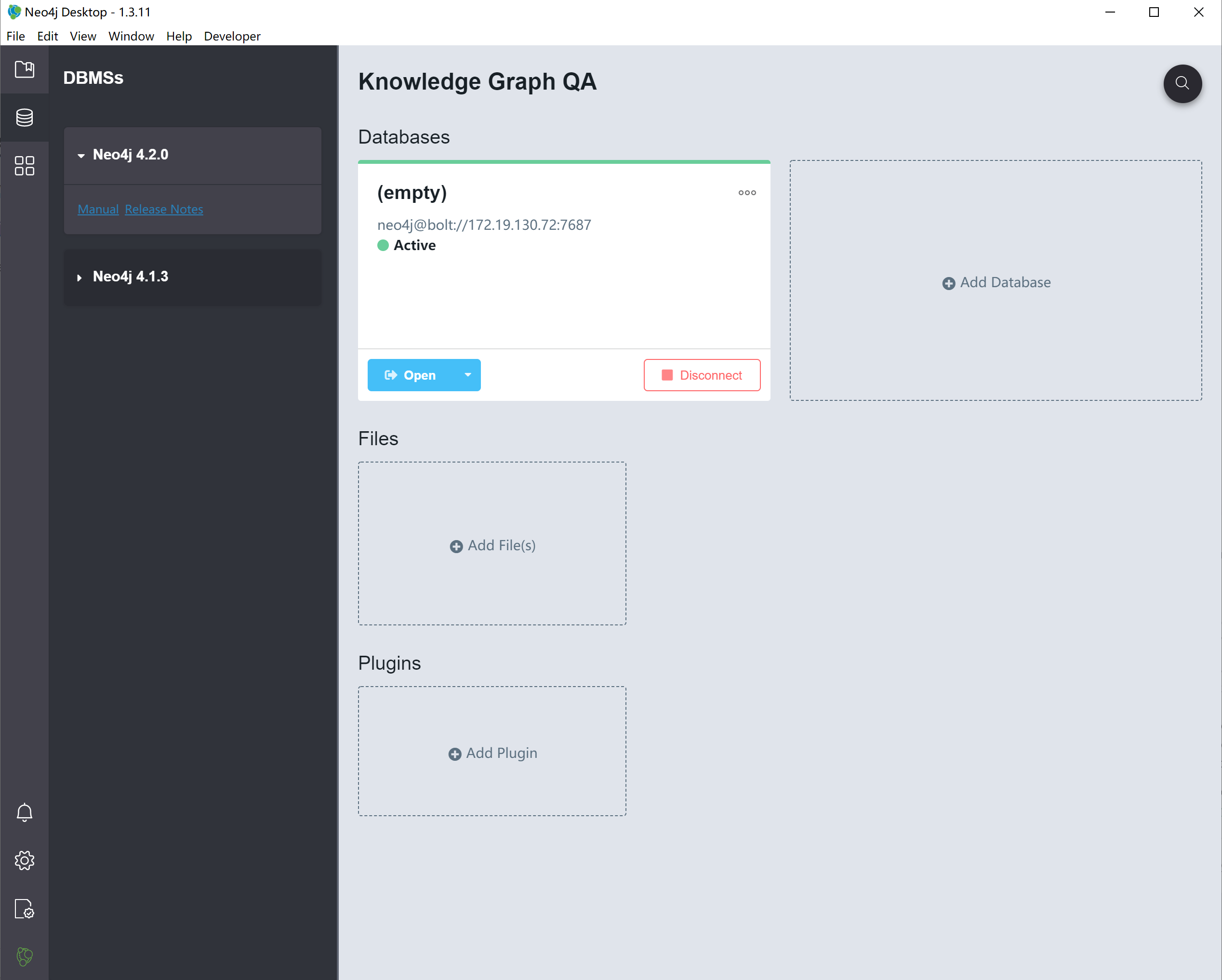
需要注意的是,有个 Neo4j Desktop 可以使用,支持多平台,他内部与 neo4j server 是通过自有协议 bolt 连接起来的,看起来大概是这个样子,端口也是 7687,而不是我们平时通过浏览器 http 协议的 7474 端口。
使用这个 desktop 版本的好处是,方便管理插件,方便连接远程服务,其他的就和浏览器访问没有什么差别。
当然,我们最可能在生产上使用的,应该是 Server 版本,这里以 Community Server Debian Packages 为例。
首先,添加 apt 源:
$ wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -echo 'deb https://debian.neo4j.com stable latest' | sudo tee /etc/apt/sources.list.d/neo4j.list
接着,搜索一下都有哪些版本
$ apt list -a neo4j
我这里列出的有 4.2.1 和 4.2.0 是最新版本,这里我们选择新版本。注意在安装指导页,有这样一个提示:
This is a good place to start if you are unsure, but we do not recommend this for production or business critical installations.
意思是最新版不适合生产环境,具体原因没有说明。但是其实 4.2.x 他都是不推荐的,目前最好使用 4.0,但是我们这里是学习的目的,也就无所谓版本过高了。
具体不推荐的原因我猜测是
4.2 要求 jdk 11,而生产环境下使用 jdk 11 的应该不多
相关插件更新速度可能没有那么快,或者无法保证可靠性
然后,通过指定版本号,安装
$ sudo apt install neo4j=1:4.2.1
桌面版直接安装运行即可启动,server 版本,输入命令
即可启动。
启动之后可以通过浏览器访问,默认用户名和密码都是 neo4j
可以观察到上方有一个输命令的地方,使用来写 Cipher 语句的,类似于 SQL 语句,可以实现除增删改查 之外的很多功能。面板上还有两个浮动的卡片,每执行一条语句,就会多一个卡片记录历史,也可以点击卡片右上角的操作区,加入收藏,重新执行或删除卡片等。
默认的 neo4j 有以下几个问题:
只能从 localhost 访问
只能从它指定的文件夹里面导入外部数据
所以需要修改配置文件,解决这两个问题。
修改 neo4j.conf
$ sudo vim /etc/neo4j/ne4j.conf
在最后面新建一条,或者搜索里面的键,将其取消注释,修改如下
dbms.default_listen_address =0.0 .0.0 dbms.security.allow_csv_import_from_file_urls =true
在配置文件里,也可以发现如下信息:
dbms.directories.data=/var/lib /neo4j/data /var/lib /neo4j/plugins /var/log /neo4j dbms.directories.lib=/usr /share/neo 4j/lib /var/run /neo4j
这里显示了例如 plugins 文件夹所在的地方,以后我们会用上,记住这个目录 /var/lib/neo4j/plugins。
最后,重启 neo4j 使配置生效
在审查阶段,有很多实用的小方法,比如:
查看某文件的 第 2 行到第 10 行的内容(sed 命令是从第 1 行开始,而不是第 0 行)
$ sed '2,10p;d' ownthink_v2_1000.csv'1p;d' ownthink_v2_1000.csv
查看某文件里面是否出现某字词
$ grep -a "琉璃美人煞" ownthink_v2.csv
查看某文件总共有多少行
$ wc -l baike_triples.txt
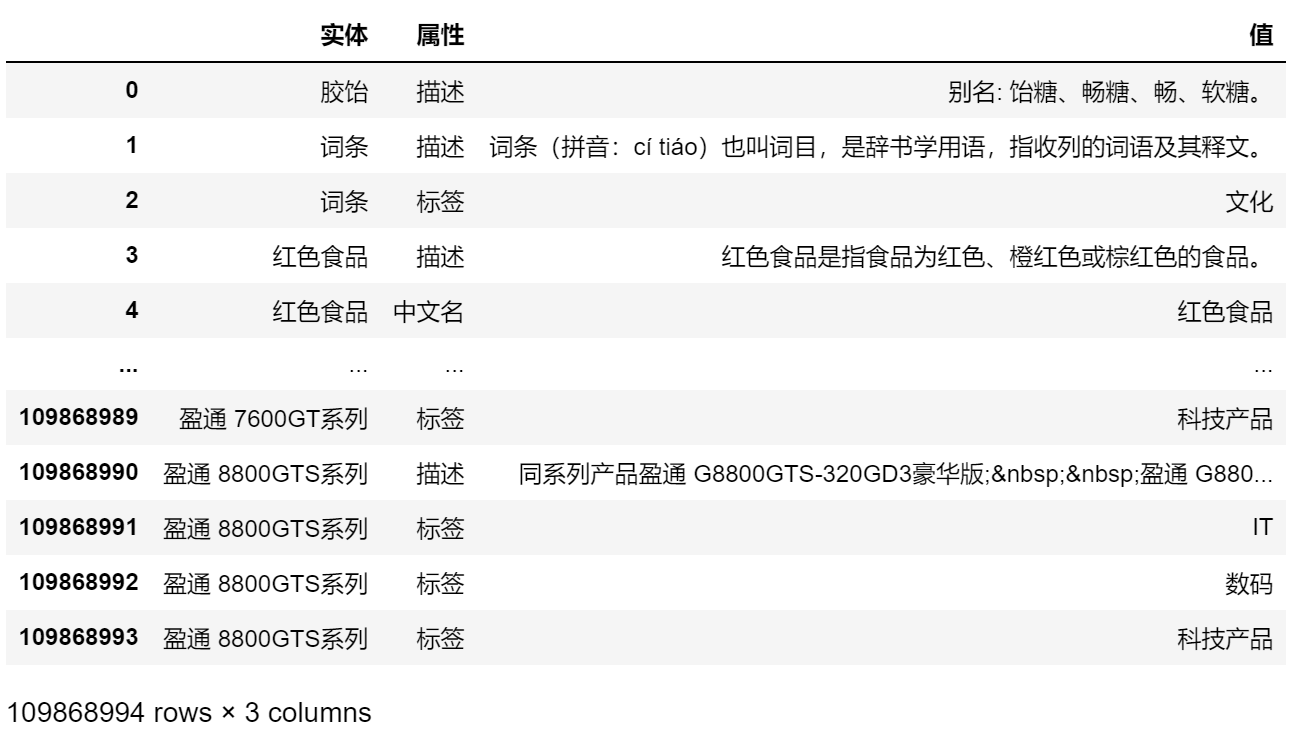
我们的知识数据格式是 csv,内容是三元组,样貌是:
在入 neo4j 之前需要清洗数据,这里简单介绍。
from tqdm import tqdm0 with open ("../data/ownthink/ownthink_v2.csv" , encoding="utf-8" ) as fin, \open ("../data/ownthink/ownthink_v2_cleaned.csv" , "w" , encoding="utf-8" ) as fout:for line in tqdm(fin, total=140919781 ):"," )if count != 2 or "歧义关系" in line or "歧义权重" in line:continue list (map (lambda x: x.strip(), line.replace('"' , '' )u"\u3000" , "" ) u"\xa0" , "" ) "【" , "" )"】" , "" )" " , "" ).split("," )))if not all (strs[:3 ]):continue if strs[0 ] == strs[2 ]:continue 0 ] + "," + strs[1 ] + "," + "," .join(strs[2 :])1 "\n" )import pandas as pd"../data/ownthink/ownthink_v2_cleaned.csv" )from collections import Counter"属性" ])list (map (lambda x: x[0 ], c.most_common(25000 )))1000 ])with open ("../data/ownthink/ownthink_v2_cleaned.csv" , encoding="utf-8" ) as fin, \open ("../data/ownthink/ownthink_v2_cleaned_rfiltered.csv" , "w" , encoding="utf-8" ) as fout:for line in tqdm(fin, total=lc):if line.split("," )[1 ] not in rs:continue
有不少无效数据,比如有空值的,属性名是 歧义关系 、歧义权重 的,还有包含不成对引号的,有 na 值的,都是不正确的 csv 格式,在导入 neo4j 的时候会出现错误。neo4j 最大支持 65536 个关系,而我们将导入的数据集关系数超过了这个界限,所以通过代码控制关系 25000 个。
关于导入 csv 的方法,neo4j 有较为完整的支持
https://neo4j.com/developer/guide-import-csv/
这里简单介绍下我的思路。既然要做知识图谱,而 neo4j 又是专门存储 实体-关系 的工具,那么,必须弄清楚,csv 文件里的三元组(实体,属性,值),他们谁是 实体 ,谁是 关系 ,答案是显而易见的。实体 和 值 都是 neo4j 里面的节点,属性 是关系。
为测试导入,取 ownthink_v2.csv 前 1000 行,进行 cypher 语句的编写。
$ sed -n '1,1000p;1001q' ownthink_v2.csv > ownthink_v2_1000.csv
所谓知识图谱,就是实体与实体之间的关系 ,但是因为数据是从网上百科爬来,有很多值 ,都不是单纯的实体,而是一句描述性的话语,比如:
雁荡山(实体),特点(属性),芦苇茂密,结草为荡(值)。
如不经过精细的清洗和对齐,将构成非常冗余的图节点,比如 浙江省温州市和台州市南部 一节点既包含省市也包含方位。用来做知识问答当然没问题,但是就图存储来说,确实是不优雅的。
在这里我们省去繁琐的数据清洗、知识补全、知识推理的过程。在上小节中,我们使用 python Counter 生硬的只保留了最常见的 25000 个关系。
首先,我们清空 Entity 类型的节点。
match (e: Entity) detach delete e;
然后,创建 Entity 的 name 字段唯一性约束。
CREATE CONSTRAINT ON (n:Entity) ASSERT n.name IS UNIQUE;
然后我们就能正式导入数据了。
:auto USING PERIODIC COMMIT 100
关于如何加载 csv 文件导入,可以参考这两篇:
这里使用到了插件 APOC 的 apoc.do.when 和 apoc.create.relationship 过程,需要提前安装他。
可以在 https://github.com/neo4j-contrib/neo4j-apoc-procedures/tags 这里下载合适的版本,放在 /var/lib/neo4j/plugins 目录下。然后重启 neo4j。
这两个过程的使用文档,可以在这里看到:
其中 apoc.do.when 的作用是 if-else 的判断作用,如果当前行的属性 是“描述”,那么说明,应该插入一个实体 ,其有个描述 字段,而不是插入两个实体 ,关系是描述 。
CALL apoc.do.when(
CALL apoc.do.when(
其中 apoc.merge.relationship 的作用是,根据 csv 中读出来的属性 关系,在两个实体 之间创建一个新的关系 。neo4j 默认不支持使用变量来命名关系 ,所以需要使用这个插件的过程 来实现。merge 下的 relationship 不会创建重复的关系 。
CALL apoc.merge.relationship(e1, row["属性"], {}, {}, e2) YIELD rel
如果使用 Cypher load csv 的方式导入数据,数据量太大(超过1千万行),即使使用了 :auto USING PERIODIC COMMIT 100 也可能出现一系列的问题,比如浏览器超时崩溃。(有可能是因为我使用 wsl2 通过 /mnt 目录进行文件 I/O 的原因。)
可以使用 python 代码来控制写入的过程,配合 pandas 也能实现小批次事务 写入。
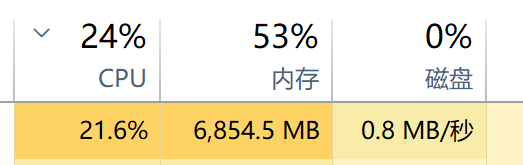
实测,chunksize=10000,执行同样的 Cypher 语句,对计算机的物理资源占用如下
import pandas as pdfrom neo4j import GraphDatabase"bolt://localhost" , auth=("neo4j" ,"password" ))with driver.session() as session:"../data/ownthink/ownthink_v2_cleaned_rfiltered.csv" 10000 )for i, rows in enumerate (row_chunks):"Chunk {}" .format (i))'records' )def upsert (tx, p ):""" unwind $rows as row with row CALL apoc.do.when( row["属性"] = "描述", 'merge (e1:Entity {name: row["实体"]}) set e1.description = row["值"] return e1 as e', 'merge (e1:Entity {name: row["实体"]}) \n merge (e2:Entity {name: row["值"]}) \n with e1, e2, row \n CALL apoc.merge.relationship(e1, row["属性"], {}, {}, e2) \n YIELD rel \n return rel as e', {row:row}) YIELD value return value.e """ , rows=p)
简单的的 api 文档可以在 https://neo4j.com/docs/api/python-driver/current/#quick-example 找到。
查看 25 个:
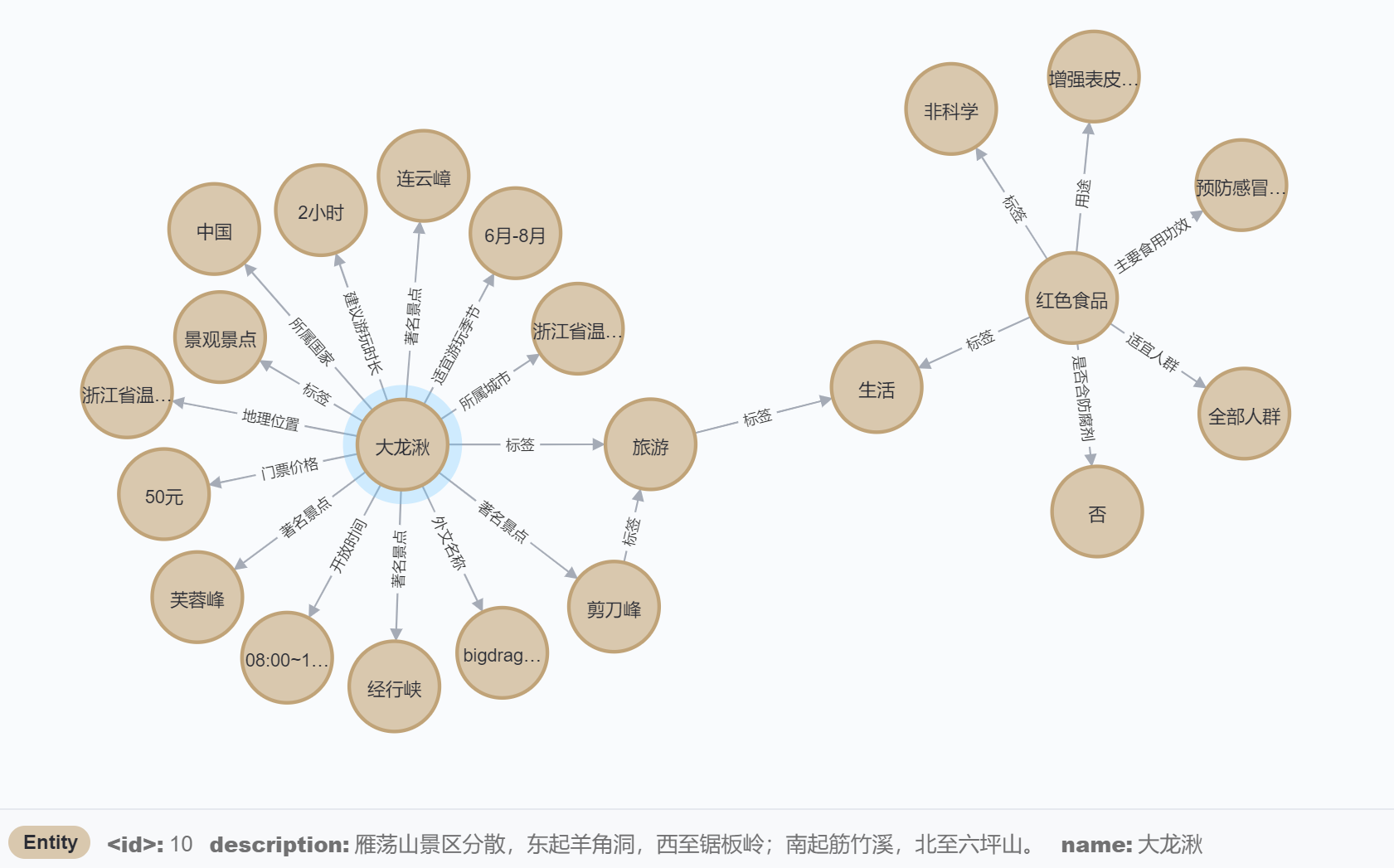
MATCH (n:Entity) RETURN n LIMIT 25
可以看到节点与节点之间的关系和节点的 name 和 description
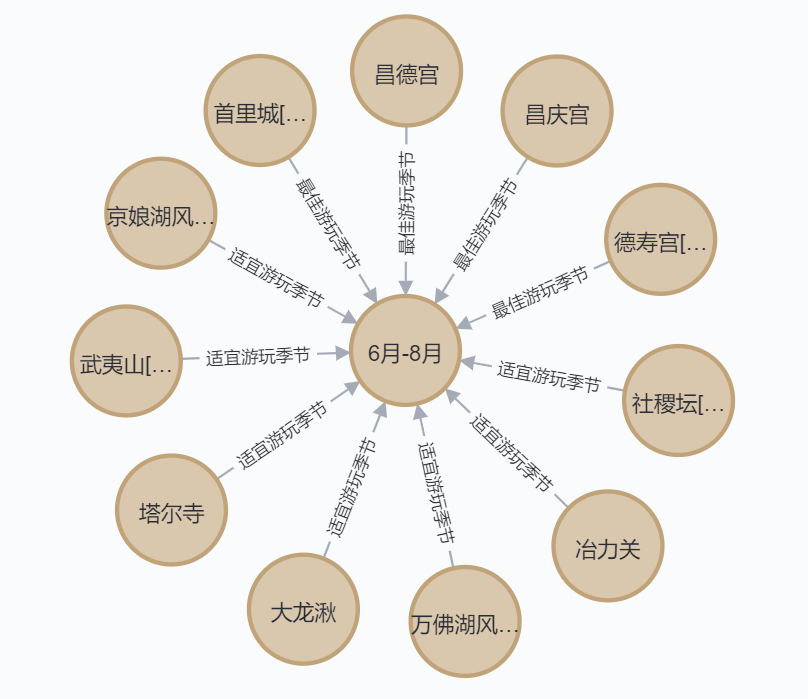
查看 6月-8月 适合的地方:
MATCH p=()-[r]->(:Entity{name: "6月-8月"}) RETURN p
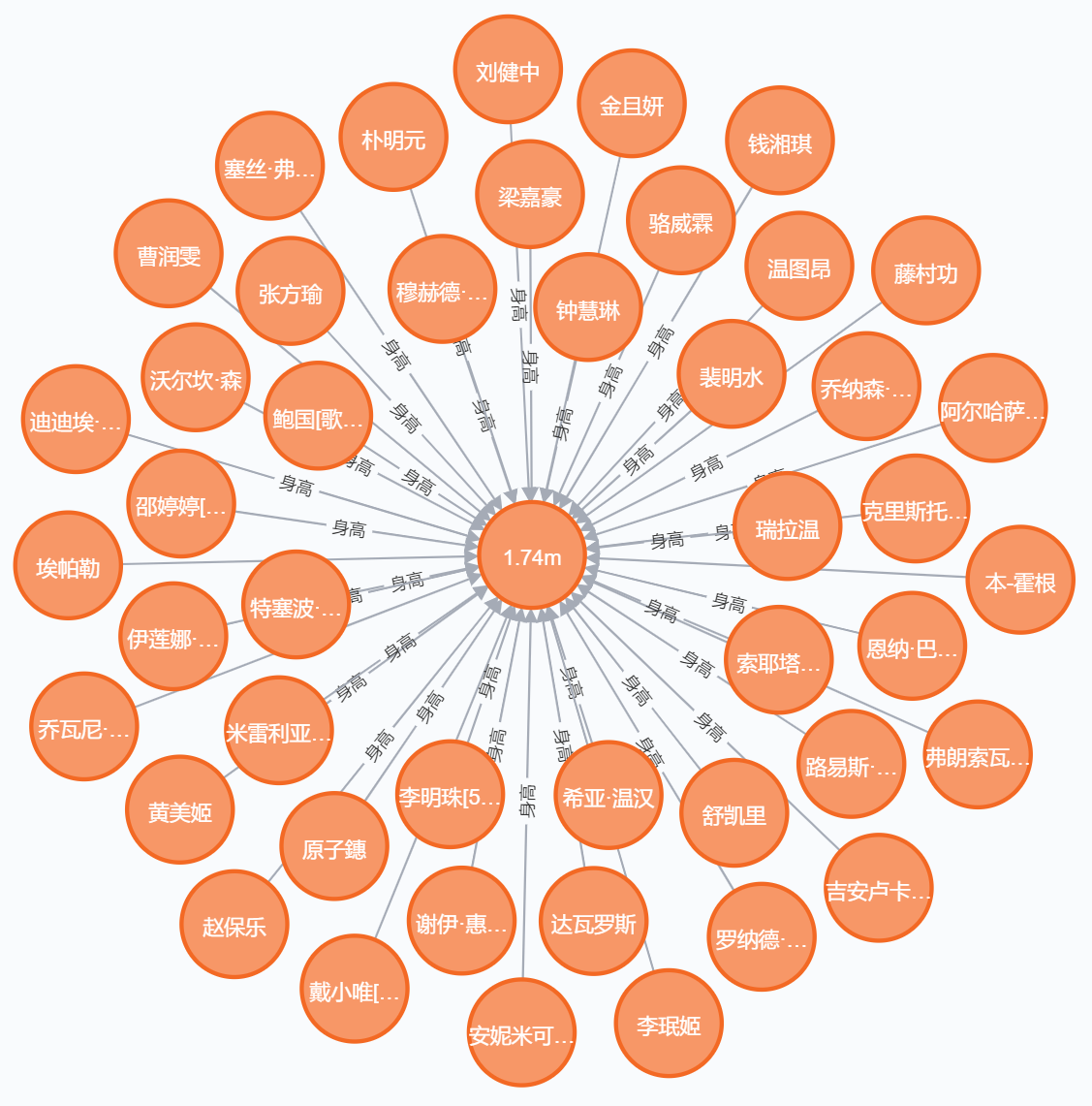
查看 身高 是 1.74m 的:
MATCH p=()-[r:`身高`]->(e:Entity{name: "1.74m"}) RETURN p
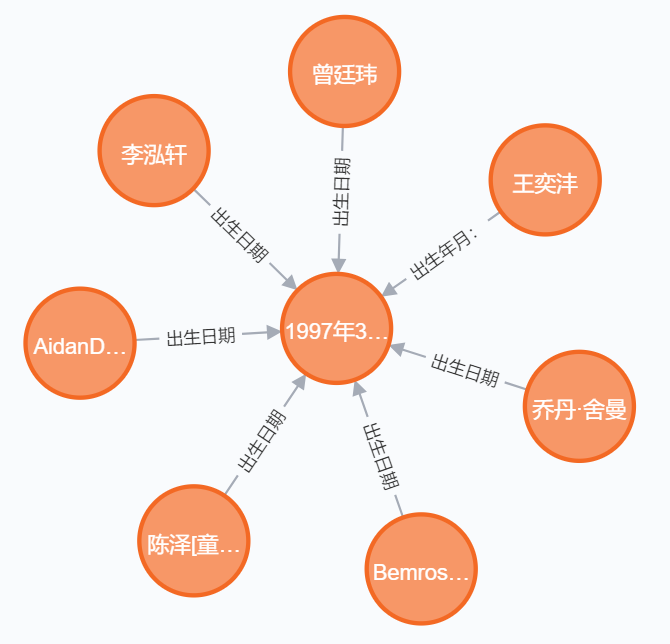
查询 1997年3月27日 出生的人
MATCH p=()-[r]->(e:Entity) where e.name in ["1997年03月27日", "1997年3月27日"] and type(r) in ["出生日期", "出生年月:"] RETURN p