
前言
在 中英双语论文解析:Mining Frequent Patterns without Candidate Generation(挖掘没有候选者生成的频繁模式) 和 Spark大数据第一步:关联规则挖掘须知,什么是支持度、置信度 两篇文章的加持下,我想,现在对于深入理解经典的购物篮关联规则分析的原理已经不再是一件困难的事情。
代码分析
数据准备
设 mb 为 market basket (超市购物篮)的缩写,作为文件名,其内容如下:
|
我们将其使用 $ hadoop fs -put 命令或 hue 网页端,将 mb 文件上传到 HDFS
读取数据
本文我们将使用 python 语言进行开发,所以在 spark 的机器上面打开 pyspark
|
将 mb 文件以文本读取进来,然后转为 rdd 进行分割,使 hdfs 里面的文件变成一个 rdd,我们称之为 mbrdd (market baskets rdd)。
创建 DataFrame
使用 pyspark 自有的 API createDataFrame来通过指定 rdd 创建一个新的 DataFrame。
|
我们称这个创建完成的 DataFrame 为 mbdf (market baskets data frame)。
创建 FPGorwth
首先引入 FPGrowth 这个类,然后通过指定 items 所在的列名,和最小支持度、置信度来初始化这个 FPGrowth 实例。
|
计算
使用 fit 方法来告诉 FPGrowth 实例该去处理哪些数据。
|
上述代码会输出三张表格:

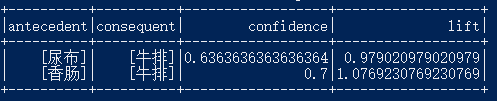

从输出的结果中,我们可以看出,买尿布或香肠的人,明显会更有可能去买牛排。
以上数据,是个人乱输的,但是也能分析出来一点的结果,可供学习使用。




